year: 2022
paper: https://arxiv.org/pdf/2212.04458
website: https://louiskirsch.com/gpicl / https://x.com/LouisKirschAI/status/1601028625893326853 / http://louiskirsch.com/ / Louis Kirsch - Towards Automating ML Research with general-purpose meta-learners @ UCL DARK
code:
connections: meta learning, transformer, grokking? (authors says they don’t think but they not sure), IDSIA, black-box optimization
Open question
does bs need to be this high also for more complex training tasks / larger models?
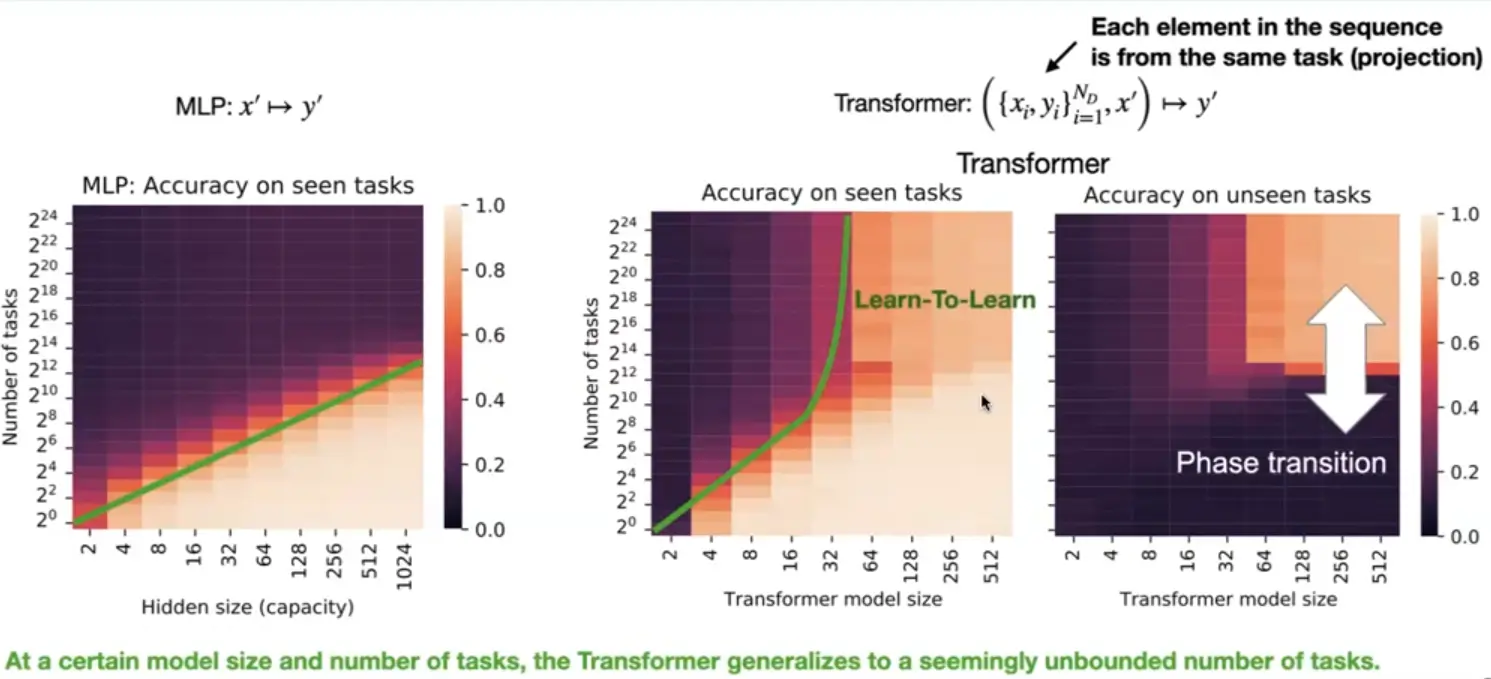
General purpose in context learners need diverse task distributions! (duh)
If you meta learn on enough tasks, suddenly you can generalize to all tasks.
Three phases: Task memorization, Task identification, Learning to learn.
Task memorization - no within-sequence improvement (lookup table)
Task identification - improvement on seen tasks only (pattern-matching)
Learning-to-learn - improvement on unseen tasks (generalization)
Image on the right: When meta-training on around 2^14 tasks (on the transition boundary) with multiple seeds, at the end of meta-training, the network either implements system identification or general learning-to-learn but rarely solutions in between. The dots are training runts with different seeds - so there is an unstable range between the two modes.
Task identification?
The name reflects the idea that the model is determining what task it’s solving (based on past learning) and then fine-tuning its behavior accordingly, even though it may not generalize well to tasks that are significantly different from those in its training set. This contrasts with memorization, where the model doesn’t recognize or learn anything about the any underlying task; it only recalls specific outputs for seen inputs.
Architectures with bigger state sizes are better general purpose meta-learners.
A case for indirect encodings? Attention is an indirect encoding.
Navigating the phase-space: High batch-size and large task-space.
Higher number of tasks → longer plateau length (harder to generalize) + bigger task batch size required.
Bigger task batch size → shorter plateau (less instability and variance in updates).
It’s easier to first memorize and then generalize, rather than trying to generalize right away!
The more you bias your batch, the faster you can learn! There is a sweetspot, where you completely avoid the loss plateau phase, by allowing the model to memorize more quickly and then generalize.
This means curriculum learning works here!
Focus on theoretical insights by creating random tasks:
In this work, we take an intermediate step by augmenting existing datasets, in effect increasing the breadth of the task distribution based on existing task regularities. We generate a large number of tasks by taking existing supervised learning datasets, randomly projecting their inputs and permuting their classification labels. While the random projection removes spatial structure from the inputs, this structure is not believed to be central to the task (for instance, the performance of SGD-trained fully connected networks is invariant to projection by a random orthogonal matrix (Wadia et al., 2021)). Task augmentation allows us to investigate fundamental questions about learning-to-learn in the regime of many tasks without relying on huge amounts of existing tasks or elaborate schemes to generate those.