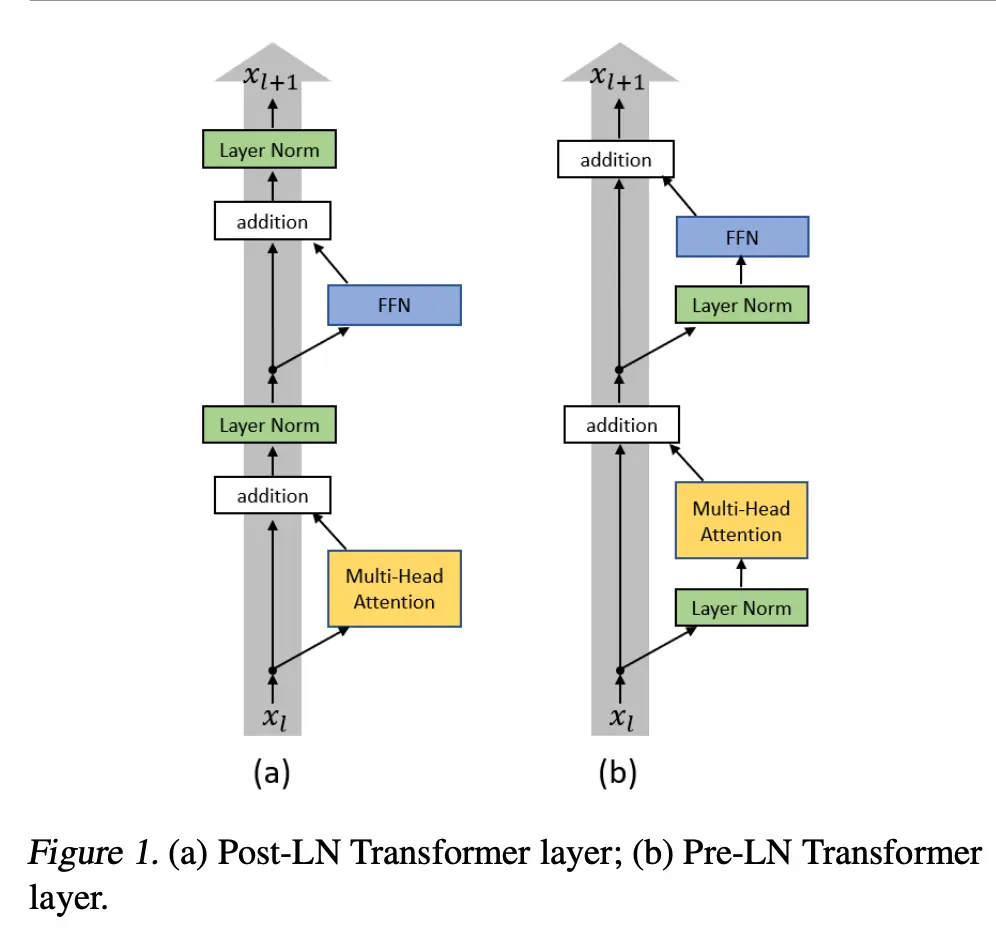
Norming the inputs of layers, instead of the outputs:
- x + self.layer_norm(self.self_attention(x, mask=mask))
+ x + self.attention(self.layer_norm(x), mask=mask)A key benefit is that the residual stays unnormalized, so the original input can flow through the entire net more easily:
class PreNorm(nn.Module):
def __init__(self, dim: int, fn: nn.Module):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)Todo