https://paperswithcode.com/paper/layer-normalization
Optimizing a Layer Normalization Kernel with CUDA: a Worklog
Types of normalization techniques in machine learning - comparison
Link to original
In contrast to batch normalization every datapoint gets normalized individually, but accross all the features (layers). Removes dependency on batch but features might have different scales.
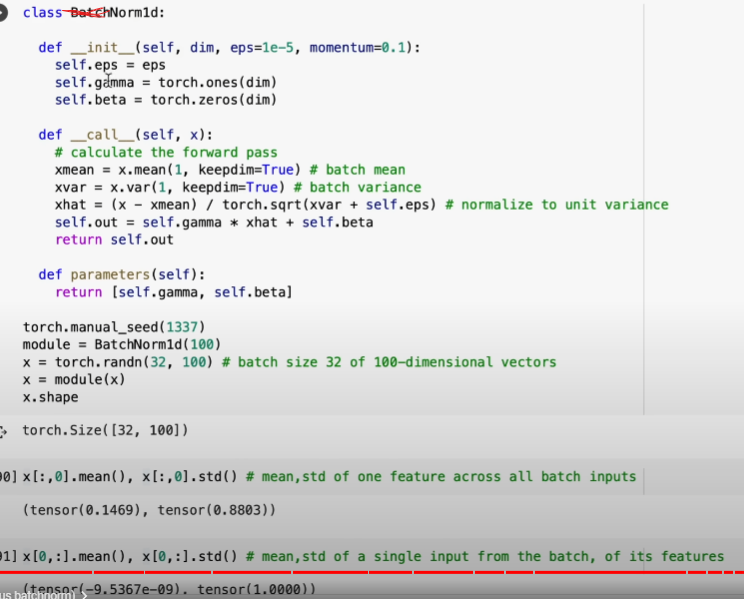
Essentially BatchNorm:
Input: Values of over a mini-batch:
Link to original
// mini batch mean
// mini-batch variance
// normalize
… noise parameter in case variance is 0 (div by 0)
Circular transclusion detected: general/batch-normalization
but better:
where is the dimensionality of and is a small number used for numerical stability.
Why?
Circular transclusion detected: general/Normalization---Scaling---Standardization
Example
Refer to batch normalization for more explanation.
layer normalization for fully connected layer , neuron and feature size
Normalize feature
… noise parameter in case var is 0, see ^cd1cd1
Scale and shift normalized feature, with learnable params:
Code
(from Karpathy)