year:
paper: https://arxiv.org/pdf/2510.25741
website: Really nice explainer video
code:
connections: transformer, LLM, latent reasoning, variational inference, ELBO, looped transformer
Training reasoning during pre-training; decoupling compute from dataset & model size.
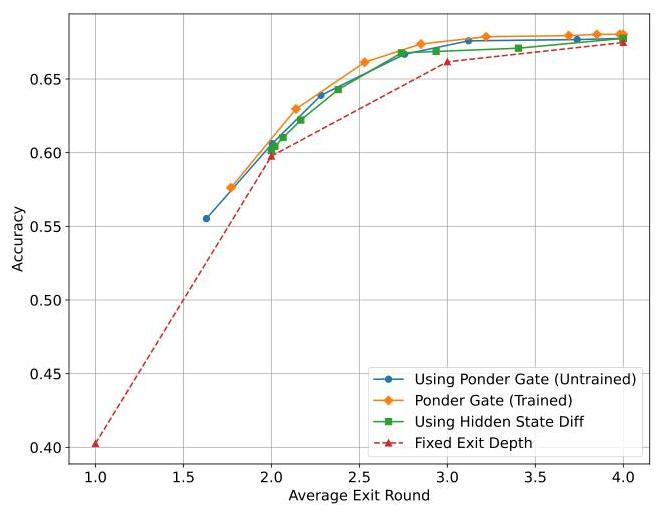
Exit gate predicts p exit, entropy regularization to encourage exploration of different exit ps.
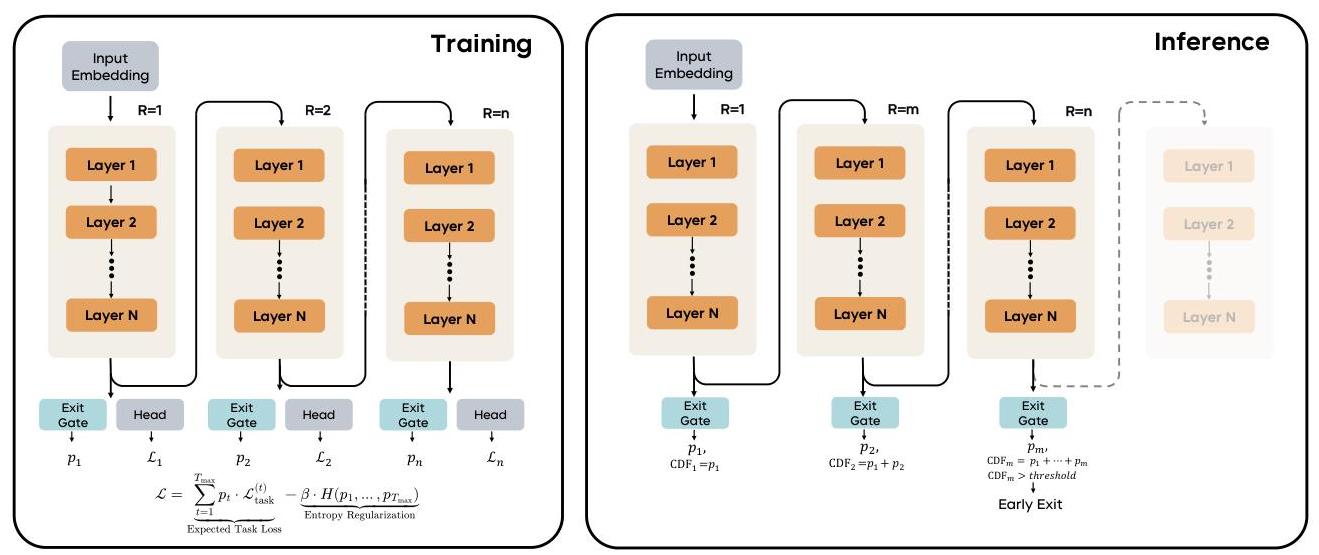

Entropy regularization for the exit gate.
Naively training by rewarding the exit gate to exit at the step with the lowest loss, leads to all the probability collapsing to a single time-step (self-reinforcing loop), like the maximum allowed timestep.
Solution: Add a KL penality for the exit gate to stay close to the uniform distribution.
Encouraging early exits via a geometric prior leads to undertraining of later steps.
read about the variational inference perspective after finishe active inference book etc.
difference to Recurrent Memory Transformer
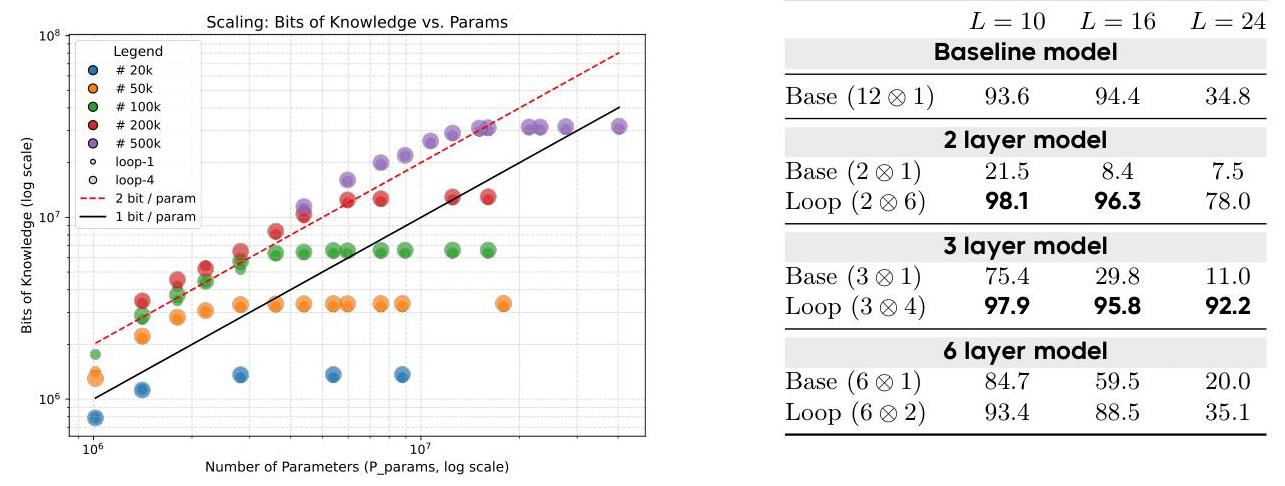
Looping does not add knowledge, but boosts reasoning: