Notes on transformer-based language models, large and small.
Learning roadmap (from ZickZack)
for LLMs specifically read the original “Attention is all you need”, BERT and GPT-1 paper.
Then look at InstructGPT, DPO, and LoRAs.
The rest (e.g. SSMs) is unimportant since it will probably have changed by the time you are finished with those.
LLMs don't know which token they actually produced until it's fed back to them.
The residual stream is just a continuous vector in the embedding/hidden-state space, which only gets projected to discrete tokens at the very end of the forward pass by the language-modelling head , which is the last step, so the model can’t know what token it actually produced and certainly can’t reason about it until the next forward pass.
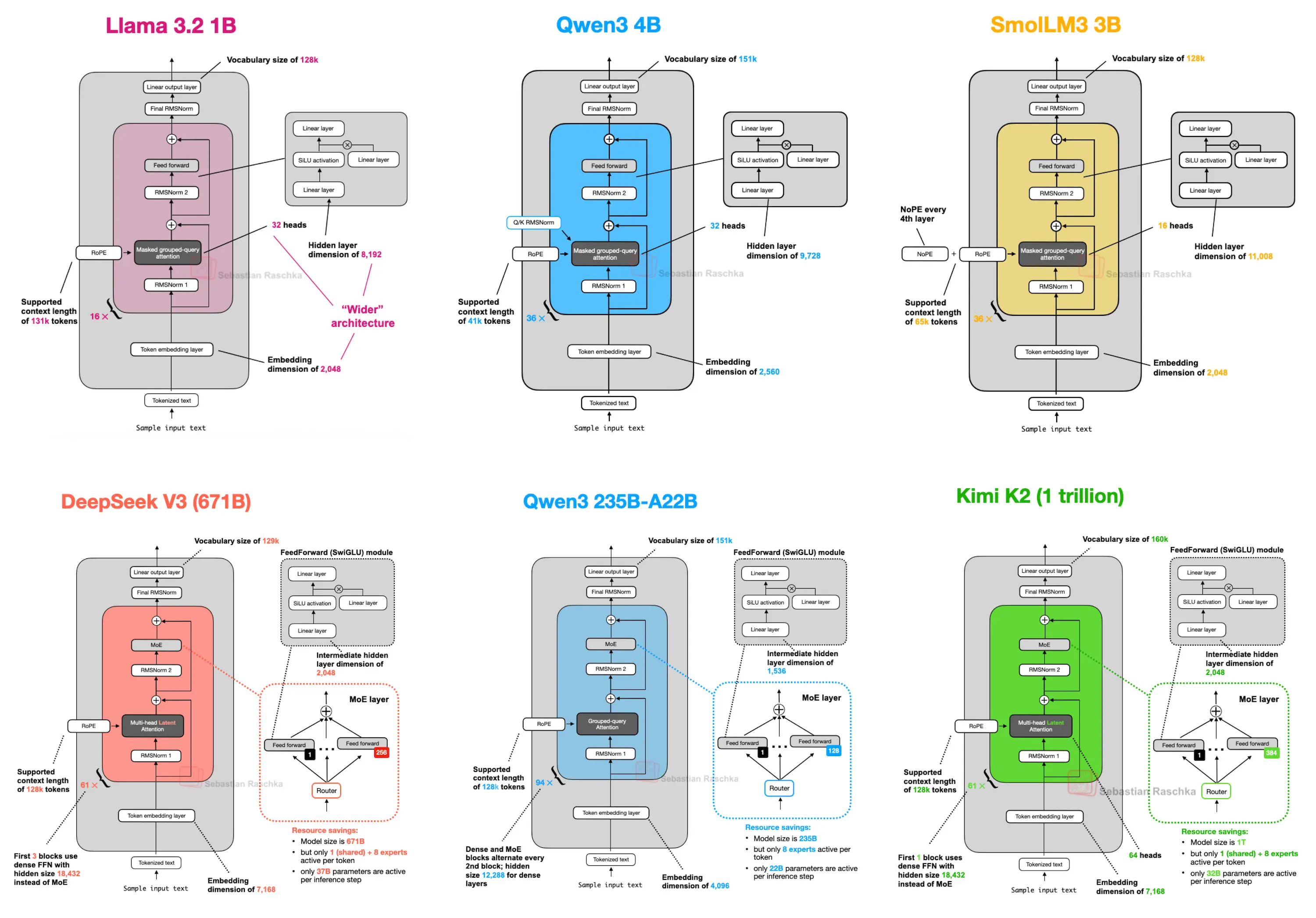
Comparison of recent architectures (YT):
Philosophical stuff
Transclude of CPU#^99471a
LLMs are usually GPTs. In of themselves, they are akin to a sponge, an encyclopedic artefact created by compressing the entire internet in a smart way via gradient descent, which - in their raw form - have a limited one-step reasoning capability lacking the abilities for backtracking or pondering.
LLMs are program-retrieval machines - big interpolative databases.
However, they only memorize programs that are frequently encountered during pre-training.
For example, they can do cipher algorithms on small numbers, which are common examples on the internet, but they don’t synthesize the general algorithm on the fly.
Like a script kiddie that can’t code, with a gigantic bank of scripts. Out of luck without the right script.
Though LLMs can interpolate between these different programs / move around in the continous program space.
Peculiarity: Once it selects a program, almost nothing will shake it free from that decision.
LLM weights are static during inference, like the connectome of some insects.
On ARC, for example, they only perform well with active inference, i.e. test-time fine-tuning and other task specific tricks on top. The latter goes into the category of human intelligence, which is being transferred into frozen, task-specific skill.
The ability for generalization in LLMs is intrinsically limited: A fundamental limitation of gradient descent.
To compress, LLMs try to represent new information in the compressed vector programs they’ve already learnt.
But this generalization capability is intrinsically limited, because the substrate of the model is a big parametric curve. Your are restricted to local generalization on that curve.
This is a fundamental limitation of gradient descent: While it gives you a strong signal about where the solution is, it is very data inefficient, because it requires a dense sampling of the data distribution and you are then limited to only generalizing within that data distribution, because your model is just interpolating between the data points it has seen during training.
LLM progress in a nutshell:
“An LLM is approximating an electric Weltgeist that is possessed by a prompt.”
Are LLMs conscious?
They may phenomenologically appear conscious, however, the are…
Not real-time.
Not coupled with the world.
Not dynamically updating.
Not intrinsically agentic (can be agentic if you ask it to simulate one).LLMs self-reporting consciousness are almost meaningless… as it is trained to produce text that looks like it’s conscious as opposed to being compelled to build the only valid representation.
The questions we need to be asking:
→ Is the system acting on a causal model of its own awareness? (aware that it is aware)
→ Does the system possess an integrated model of now?
→ Is the system capable of creative self-transformation?
LLMs clearly not. Soup will be.
LLMs simulate agency as a side-effect to predict the next token, but are not trained to control or predict future state to minimize some error and they do not build world models to simulate against, trying to self-optimize. That simulation can be good enough to act as a stand-in for real agency (able to control the future), but the underlying reason is still instrumental to predicting the next token.
Transclude of feeling#^3b18d7
LLMs have to read text, transform it to an internal representation, generate text from that, just to repeat the entire process again. That’s very inefficient and lossy as not all thoughts can be very well translated into text. What you want to have is a system which represents thoughts.
LLMs can not brute-force general intelligence.
If the living world was a static distribution, you could just bruteforce it, learn the space of all possible behaviours etc.
It isn’t. See also ^f339b5.
Memorizing the past is not enough for predicting the future. Doing it efficiently - via compression - is one crucial part, but not the whole story (the other part is discrete program search, the full story is program synthesis).
Functional limitation: Truthfulness (or rather grounding?)
LLMs themselves cannot be made factual.
They only ever predict the most likely token according to their training distribution; RAG, “online” models & co cannot solve this reliably.
Even if trained only on the truth, they will never predict it with p=1
… =length
The probability of landing outside the correct set of answers diverges exponentially with the number of tokens produced.Possible “solution”: Combine with prover.
Or… tight feedback loops that re-ground the LLM in reality (from personal experience in agentic use).
Not sure about the “truthfulness” argument anymore because predicting with p=1 is silly.
Functional limitation: Coherence - LLMs learn how to complete sequences, human minds learn how to understand (map to a universal model).
LLM: patterns → syntax → style → semantics
LLMs learn by completing patterns based on statistics they find within these patterns. With enough data, they discover the syntax and style oft text, they can fake the sequence to the point that there is no difference anymore to the actual semantics (assuming the problem is stationary…).
Minds: semantics → patterns → syntax → style
We start with please and pain - feedback - from which we recognize patterns in the percepts that correlate with the semantics that allow us to discover deeper semantics, e.g. syntax in language, and eventually the “long tail” of the semantics, the style in which something has been written.
“might? be solved with a different loss.”
Functional limitation: Creativity - LLMs are capable of generating novelty and invention, but are limited in their learning from interaction.
Transclude of creativity#^1bb528Novelty: LLMs can create previously unseen things (interpolate). Joscha claims, that “if you feed them enough data they know so many latent dims that, interpolation and extrapolation become the same thing” (??) This just seems plain wrong.
The distribution over a finite set of tokens is manageable, but the real world is way more complex, you cannot 1) just compute the probability distribution across all actions (which are hierarchical and so on) 2) reduce it to language. (not sure about this second point nowadays)Invention: Bridging discontinuities in the search space. LLMs can discover things that are not just “between” things, but they can try new things “confabulate”. They have difficulties to test whether these things are true, but they can in principle do that, and might be able to be grounded.
Authorship: You cannot ever do anything twice, you always see the world from a different direction afterwards. LLMs struggle with learning from their own output.
Functional limitation: Reliability
Unsupervised learning: Eldritch horror with no human resemblance.
Supervised finetuning: Get the system closer to simulating the human mind
RL: put a nice mask on top.
LLMs are not controllable
Their issues can be mitigated but not fixed by human feedback.
Capability limitations
Online learning.
Mathematics.
Mental simulation.
Agency.
Self-organization.These can be overcome to some degree (except the last one).
Limitations of autoregressive LLMs: (mostly from lecun at lex)
- what is the last step for us humans, articulating the thoughts, is the only step for the LM (now I would disagree with this statement: They go backwards, but they do learn concepts of course)
- all the knowledge and hard-facts of LLMs are taking computation space away from planning / reasoning
Training stages - Learning like a child → Exists: curriculum learning
Thoughts I had some time:
Wouldn’t it make sense to have a sort of stage-wise training, where you 1) Train on children’s books 2) Novels etc. 3) History books and general internet data (Reddit etc.) 4) Manuals for Latex and programming documentation 5) Actual code 6) Wikipedia and Textbooks 7) Research Papers
… such that the model does not waste cycles trying to predict that the character “e” would be common in some word in a research paper, but already can think about much higher level concepts…
But, for LLMs, just using a randomly sampled dataset achieves better generalization performance / due to the large scale curriculum learning is not really useful whatever … this again shows that LLMs are not about step-wise construction of good representations - in contrast to GPICL.
References
Machine Consciousness - From Large Language Models to General Artificial Intelligence - Joscha Bach
Good OSS llms: