year: 2020
paper: https://arxiv.org/pdf/1912.01603.pdf
website: https://danijar.com/project/dreamer/
code: https://github.com/danijar/dreamer
connections: world model, RL, danijar hafner
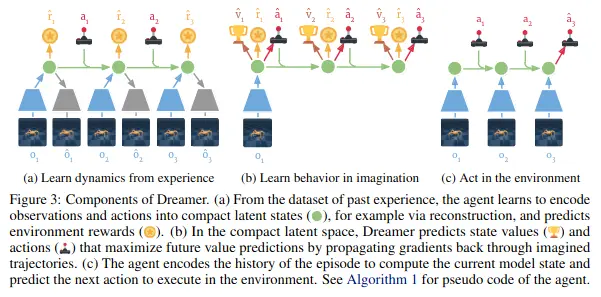
TLDR:
- Learning to plan from an encoded latent space (previous models already do that, as in (a))
- This model predicts further actions without seeing the observations (b).
- In contrast to MuZero, dreamer does this without MCTS by learning a one-shot policy that goes from observation to action, as in (c) (inference)
- In contrast to Recurrent World Models Facilitate Policy Evolution, we don’t learn from a random policy, but does the following in a loop:
- (a) learning the encoding function by sampling from the environment using the policy (initially random)
- (b) learning a good policy for the environment (in latent space)
- going back to (a) with the new policy

In the dynamics learning phase (a), are given and we want to learn a representation and a transition (to the next state) and predict the next reward.
Encoder (blue) can be a CNN and the hidden state (green) can be a LSTM for example. Use any method for the representation learning, example given in the paper/image: encoder+decoder like in a VAE, but as opposed to VAE, we are interested in the Encoder and not the Decoder, of course.
In the behaviour learning phase (b), we want to learn the action and the value parameters. We are imagining future hidden states and rewards while using the policy to choose actions. All like regular RL, but the backprop now only has to go through the small lstm network (and not through the encoder at all? or just once?).
Here, , to learn the policy net, we maximize the value target (max total future reward).
Here, , to learn the value net, we minimize the difference between the predicted value and the (ominous) value target.
value target: (workhorse of this paper, according to YK)
- many envs might have more than a couple of dozens or hundreds of steps (what an lstm could reasonably backprop through)
- the value target is the main component for extending this time-range
Finish / Update Note
Explanation left as exercise to the reader.
Seems simmilar to bootstrapping. Too tired, heading out now. TODO
Apparently:
This is called TD-lambda which essentially is the mixture of 1-step lookahead, 2-step lookahead, … H-step lookahead where H is the horizon, the same exact method is described in Sutton&Barto (eq 7.6)