year: 2021
paper: 2105-14491
website:
code:
connections: GAT, graph attention
TLDR
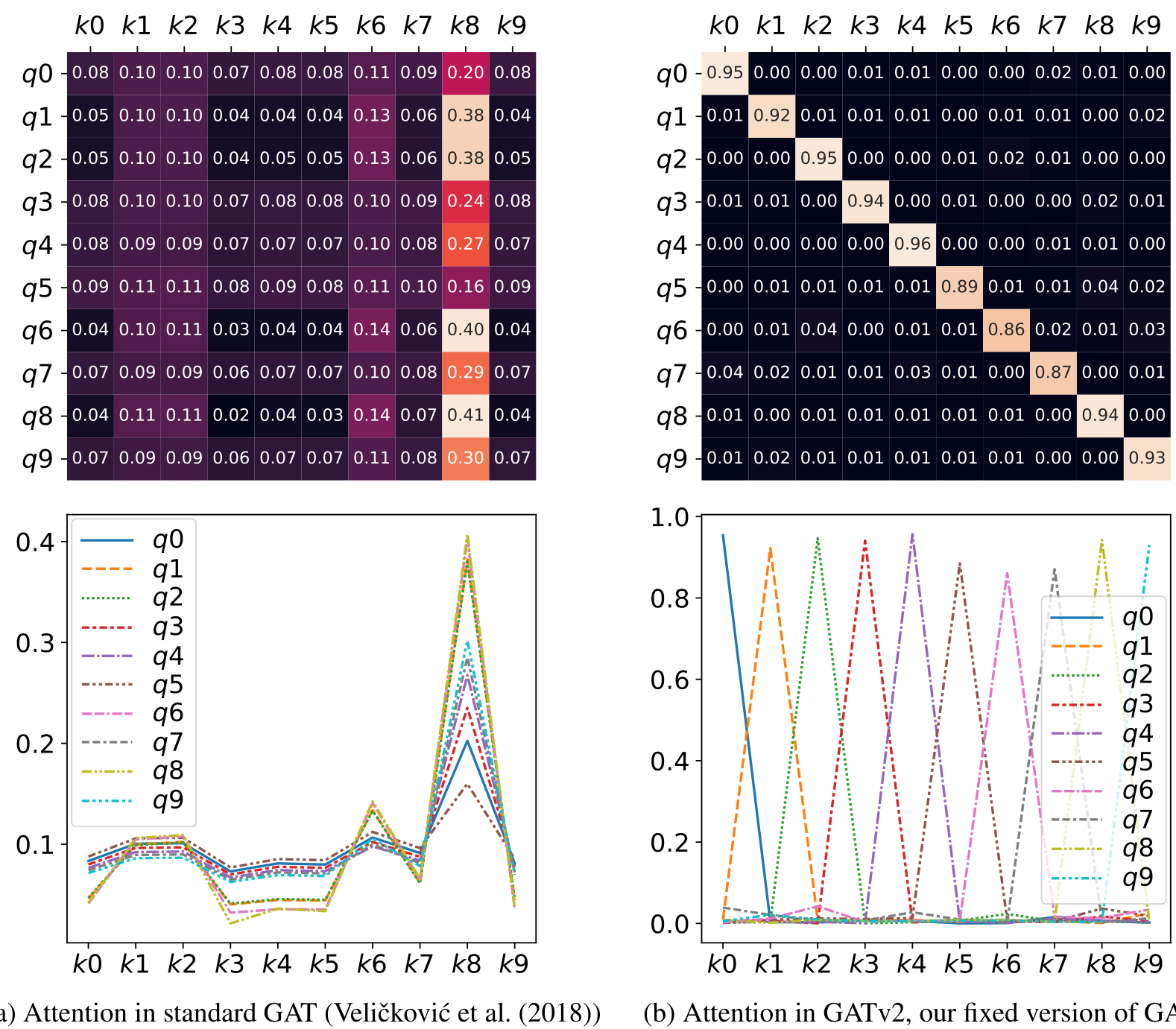
Static attention is very limited because every function has a key that is always selected, regardless of the query. Such functions cannot model situations where different keys have different relevance to different queries.To overcome the limitation we identified in GAT, we introduce a simple fix to its attention function by only modifying the order of internal operations. The result is GATv2 – a graph attention variant that has a universal approximator attention function, and is thus strictly more expressive than GAT. The effect of fixing the attention function in GATv2 is demonstrated in Figure 1b.
Dynamic attention can select every key using the query , by making the maximal in . Note that dynamic and static attention are exclusive properties, but they are not complementary. Further, every dynamic attention family has strict subsets of static attention families with respect to the same and .
Figure 1: In a complete bipartite graph of “query nodes” and “key nodes” : standard GAT (Figure 1a) computes static attention – the ranking of attention coefficients is global for all nodes in the graph, and is unconditioned on the query node. For example, all queries ( to ) attend mostly to the 8th key (). In contrast, GATv2 (Figure 1b) can actually compute dynamic attention, where every query has a different ranking of attention coefficients of the keys.
GATv2 The main problem in the standard GAT scoring function (Equation (2)) is that the learned layers and are applied consecutively, and thus can be collapsed into a single linear layer. To fix this limitation, we simply apply the layer after the nonlinearity (LeakyReLU), and the layer after the concatenation, effectively applying an MLP to compute the score for each query-key pair:
Notation
… input feature dimension
… output (projected) feature dimension
… input node features
… learned linear projections (GAT shares one ; GATv2 uses separate or optionally shares them (in ablations to eliminate unfairness d.t. increased parameter count))
(GAT) or (GATv2) … learned scoring vector
… raw attention score for edge
… normalized attention weight (softmax of )
… neighbors of node
… concatenation
… number of attention heads
Why GAT is static
Via linear map over concatenation, GAT’s scoring decomposes:
The query and key contributions are independent scalars that add. LeakyReLU is monotonic, so the ranking of over keys is determined entirely by . The query term shifts all scores by the same constant, which vanishes after softmax. Every query “agrees” on which key matters most.
This decomposability also makes GAT faster than its declared : the per-node scores can be precomputed once for all nodes, so the -term reduces to additions. GATv2 cannot merge its layers (the nonlinearity sits between them), so it actually runs at the declared complexity.
Expressiveness of dot-product scoring
Dot-product attention computes , a bilinear map in and .
This limits the scoring function to pairwise multiplicative interactions between input features.In contrast: GATv2’s MLP scorer is a universal approximator, making it strictly more expressive as a single-layer scoring function. The paper proves DPGAT (dot-product graph attention) is strictly weaker than GATv2.
The post-attention MLP in a transformer block does not compensate: it transforms the already-aggregated output. Deep stacking can compensate across layers (reshape representations so later dot-products route better) but does not change the fundamental limitation of the scoring function at each layer.
V1 vs V2:
def forward(self, h, adj):
- g = rearrange(self.W(h), "n (heads d) -> n heads d", heads=self.n_heads)
- e = self.leaky_relu(self.a_l(g)[:, None] + self.a_r(g)[None, :]).squeeze(-1)
+ g_l = rearrange(self.W_l(h), "n (heads d) -> n heads d", heads=self.n_heads)
+ g_r = rearrange(self.W_r(h), "n (heads d) -> n heads d", heads=self.n_heads)
+ e = self.a(self.leaky_relu(g_l[:, None] + g_r[None, :])).squeeze(-1)
e = e.masked_fill(adj == 0, float("-inf"))
alpha = self.dropout(e.softmax(dim=1))
- out = torch.einsum("ijh,jhd->ihd", alpha, g)
+ out = torch.einsum("ijh,jhd->ihd", alpha, g_r)class GATv2(nn.Module):
def __init__(self, in_features: int, out_features: int, n_heads: int, is_concat: bool = True, dropout: float = 0.6,
negative_slope: float = 0.2, share_weights: bool = False):
super().__init__()
self.n_heads = n_heads
self.is_concat = is_concat
self.head_dim = out_features // n_heads if is_concat else out_features
self.W_l = nn.Linear(in_features, self.head_dim * n_heads, bias=False)
self.W_r = self.W_l if share_weights else nn.Linear(in_features, self.head_dim * n_heads, bias=False)
self.a = nn.Linear(self.head_dim, 1, bias=False)
self.leaky_relu = nn.LeakyReLU(negative_slope)
self.dropout = nn.Dropout(dropout)
def forward(self, h: Float[Tensor, "n fin"], adj: Float[Tensor, "n n 1"]) -> Float[Tensor, "n fout"]:
g_l = rearrange(self.W_l(h), "n (heads d) -> n heads d", heads=self.n_heads)
g_r = rearrange(self.W_r(h), "n (heads d) -> n heads d", heads=self.n_heads)
e = self.a(self.leaky_relu(g_l[:, None] + g_r[None, :])).squeeze(-1)
e = e.masked_fill(adj == 0, float("-inf"))
alpha = self.dropout(e.softmax(dim=1))
out = torch.einsum("ijh,jhd->ihd", alpha, g_r)
if self.is_concat:
return rearrange(out, "n heads d -> n (heads d)")
return out.mean(dim=1)