year: 2018/02
paper: https://arxiv.org/pdf/1710.10903 | graph-attention-networks
website: https://nn.labml.ai/graphs/gat/index.html
code: https://github.com/gordicaleksa/pytorch-GAT | https://pytorch-geometric.readthedocs.io/en/stable/generated/torch_geometric.nn.conv.GATConv.html
connections: graph attention, GNN
TLDR
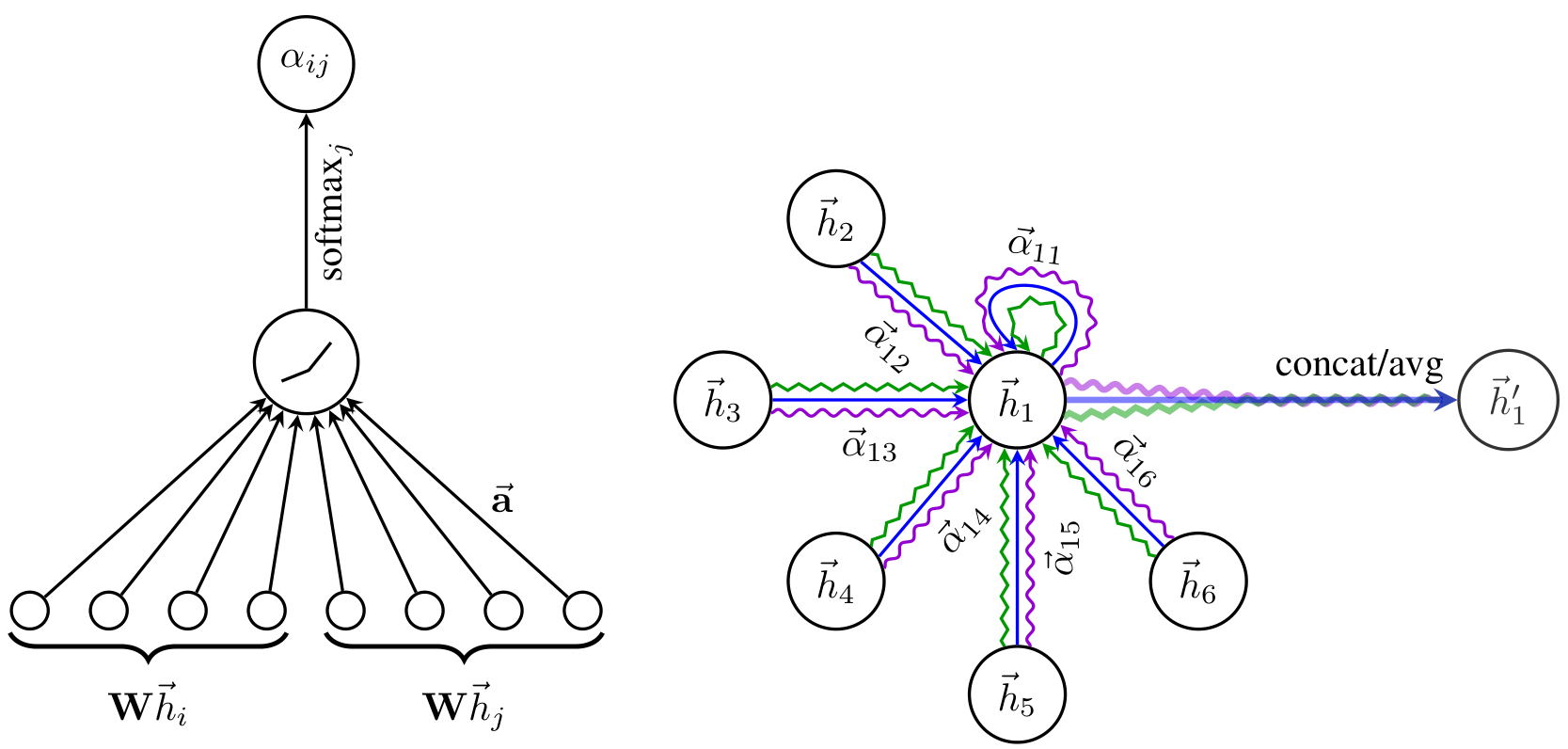
Each node scores its neighbors via a shared scoring function, softmax-normalizes, and aggregates neighbor features with those weights.
Node features are linearly projected, then each (self, neighbor) pair is concatenated and scored by a single learned weight vector.
The multi-head variant concatenates outputs from independent attention heads.
(3 squiggly lines illustrate K=3 MHA)
Notation
… input features of node
… output features of node
… shared linear projection (applied to every node)
… learned weight vector for scoring (the “attention” parameters)
… neighbors of node (from the graph adjacency)
… raw attention score between nodes and
… normalized attention weight (softmax of over )
… concatenation
… nonlinearity (ELU in the paper)
… number of attention heads
Mechanism
is concatenation.
Graph structure is injected by only computing for (masked attention).
Star topology: each node scores against its own neighbors individually, no neighbor-to-neighbor interaction.Multi-head ( heads, intermediate layers):
Final layer averages instead of concatenating.
class GAT(nn.Module):
def __init__(self, in_features: int, out_features: int, n_heads: int, is_concat: bool = True, dropout: float = 0.6, negative_slope: float = 0.2):
super().__init__()
self.n_heads = n_heads
self.is_concat = is_concat
self.head_dim = out_features // n_heads if is_concat else out_features
self.W = nn.Linear(in_features, self.head_dim * n_heads, bias=False)
self.a_l = nn.Linear(self.head_dim, 1, bias=False)
self.a_r = nn.Linear(self.head_dim, 1, bias=False)
self.leaky_relu = nn.LeakyReLU(negative_slope)
self.dropout = nn.Dropout(dropout)
def forward(self, h: Float[Tensor, "n fin"], adj: Float[Tensor, "n n 1"]) -> Float[Tensor, "n fout"]:
g = rearrange(self.W(h), "n (heads d) -> n heads d", heads=self.n_heads)
e = self.leaky_relu(self.a_l(g)[:, None] + self.a_r(g)[None, :]).squeeze(-1)
e = e.masked_fill(adj == 0, float("-inf"))
alpha = self.dropout(e.softmax(dim=1))
out = torch.einsum("ijh,jhd->ihd", alpha, g)
if self.is_concat:
return rearrange(out, "n heads d -> n (heads d)")
return out.mean(dim=1)Why ”+” isntead of “torch.cat”? → Better time complexity than the paper states
Link to originalSelf-attention?
What makes it Self- attention is, that the K, Q and V are all coming from the same source , the input.
Keys and Values can also come from an entirely seperate source / nodes: cross-attention.NOTE: Before self-attention became synonymous with “QKV scaled dot-product attention”, it just meant “a set attends to itself” (e.g. GAT, which does not use QKV but still calls it “masked self-attention”)