Todo
https://distill.pub/2021/understanding-gnns/ after reading more about (graph) laplacian (&maybe the convex optimization book).
A GNN is an optimizable transformation on all attributes of the graph (nodes, edges, global-context) that preserves graph symmetries (permutation invariances).
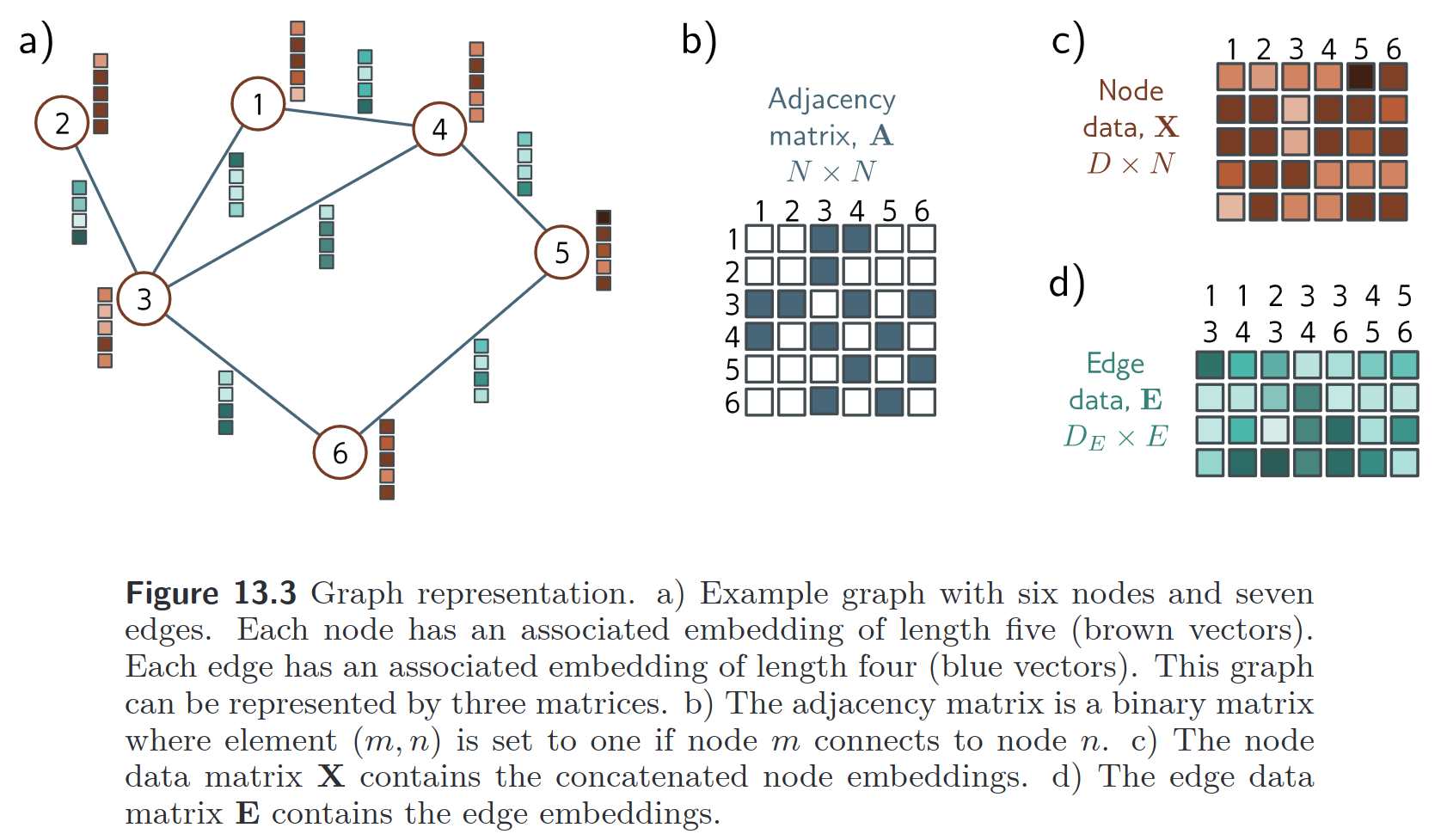
Graph neural networks are a family of neural networks that can operate (naturally) on graph-structured data.
GNN MPNN graph attention {GAT, GATv2, graph transformer, GCN, …}
MPNNs mostly differ in how they aggregate neighbor information.
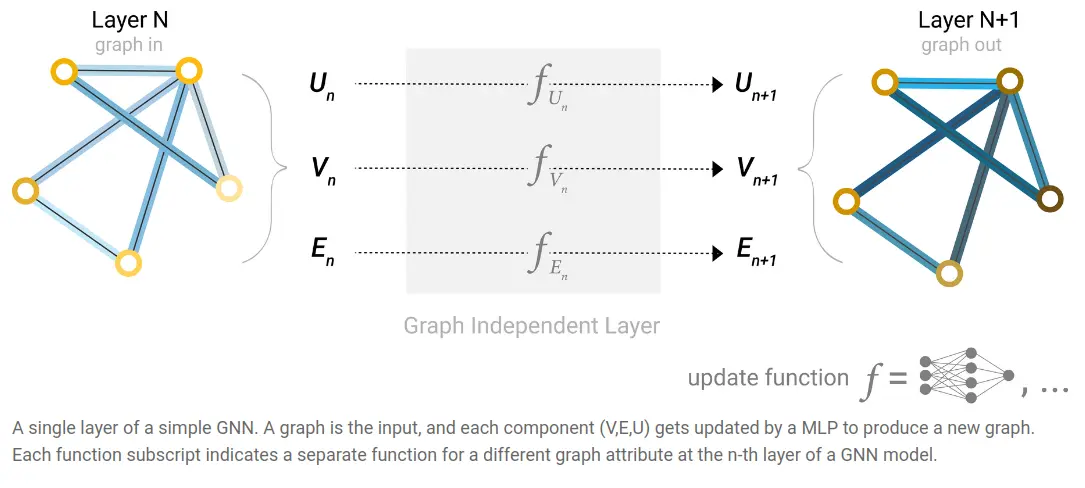
A simple GNN
There is a network for each of the features (nodes, edges, global), and each network is applied to each node embedding, edge embedding, global features independently, and repeatedly (for nodes and edges).
Here, the output has the same structure - described by the same adjacency list - so the node / edge / global feature vectors get replaced by learned embeddings.
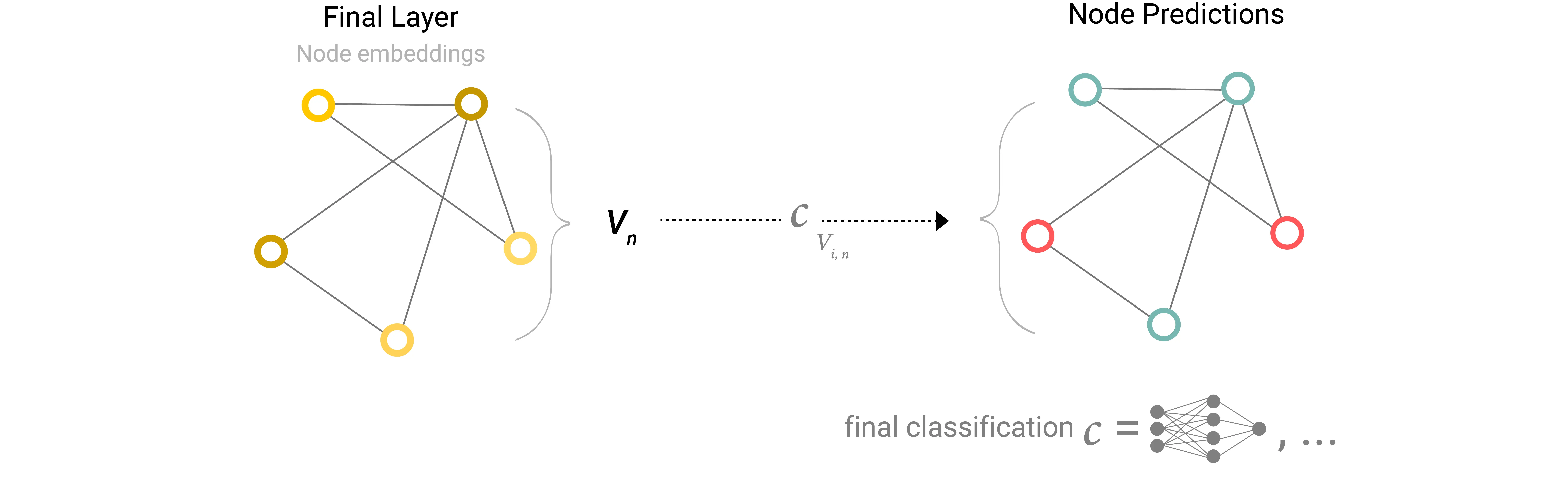
For classification, we can then simply apply the same classifier network for each node embedding:
If we only have edge features or only node features, etc. we can pool the ones corresponding to a node / edge together to get an embedding for the node. Pooling in his case can be addition for example, in order to keep the dimension the same
Note: In this simple example every node/edge/global is processed independently - connectivty only comes into play with pooling.
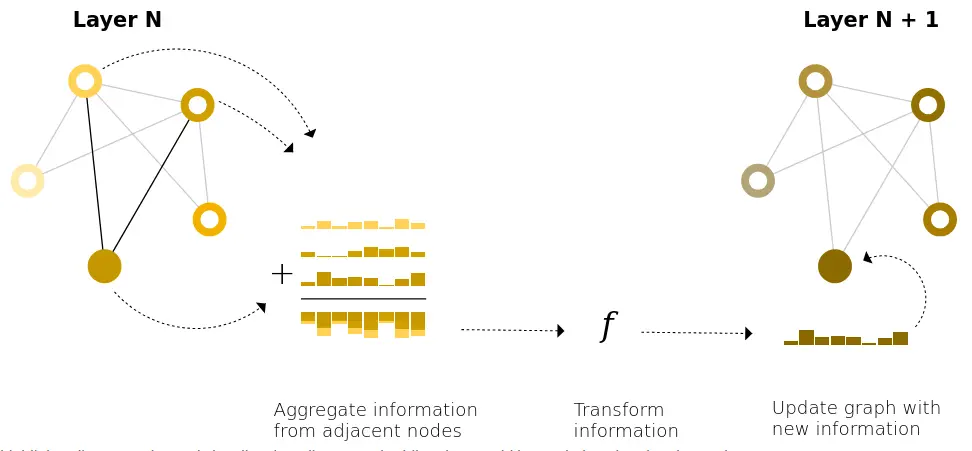
“message passing” is a lot simpler than I thought…
Link to originalA simple type of “message passing” in GNNs is simply aggregating information from adjacent nodes to compute the next embedding for a node (in conjunction with the nodes own embedding).
For a GNN with layers, each node can aggregate information from nodes steps away.
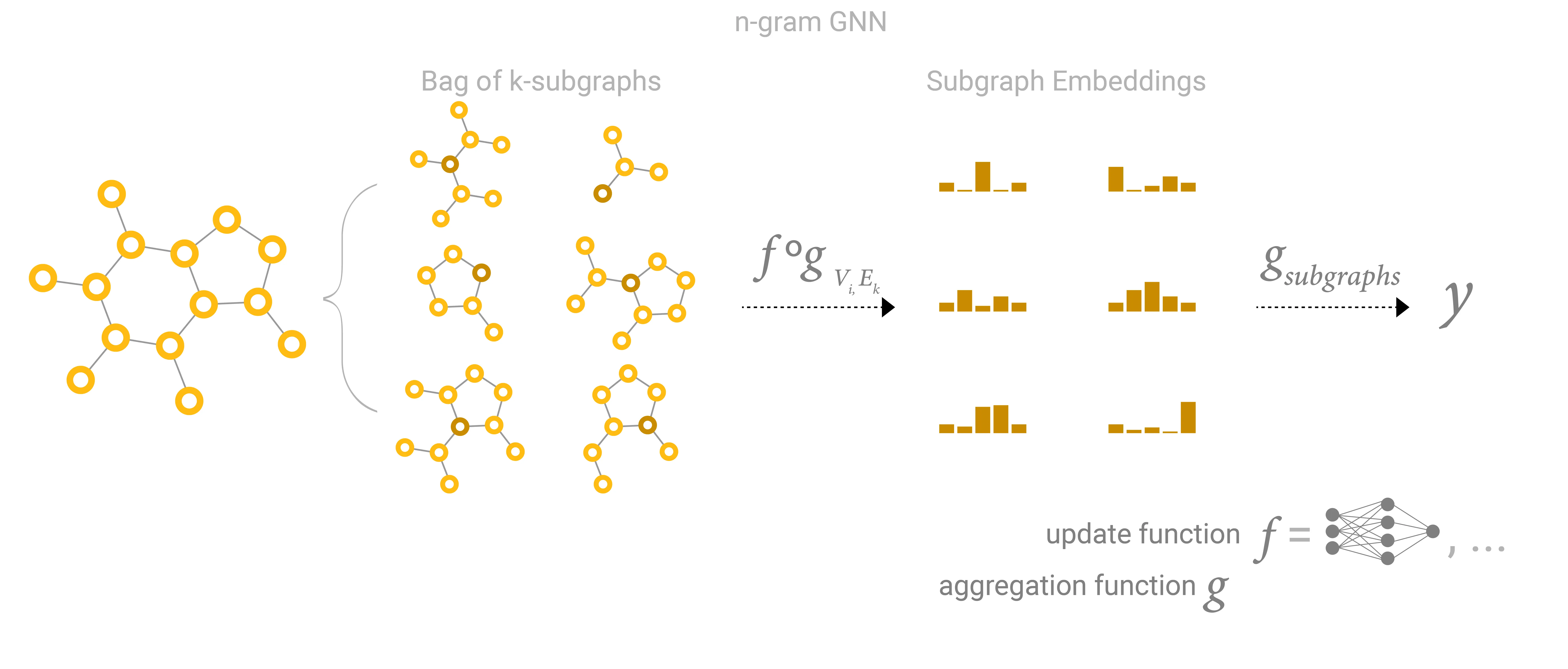
This can also be viewed as collecting all possible subgraphs of size and learning vector representations from the vantage point of one node or edge:
For large graphs, it may become infeasible (or even detrimental - see below) to add enough layers for every node to communicate with eachother, however, you can add a global context vector / master node / global representation which acts like a bridge for communication between nodes.
(See the full msg passing note…)
… representation of node after the iteration.
Message passing networks in torch geometric
Link to originalTransformer == MPNN
NOTE: the thing in the middle is NOT the “GAT” (but a scaled-dot-product form of graph attention, which GAT doesnt use, and which is actually weaker than GATv2). And the “standard GNN” is a MPNN, specifically.
Point is: Standard transformers/LLMs perform message passing on complete graphs of tokens, with SDP attn as the aggregation.
Source 1 2
References