how-to-build-conscious-machines
Bennett proves that optimal learning requires choosing the weakest (most general) hypothesis, not the simplest. This "w-maxing" principle outperforms occam’s razor by 110-500% in experiments. From this foundation, he builds up from basic physics to explain why consciousness exists and how to engineer it.
What is consciousness
Things change.
Without change, there would be no difference between states. Without difference, nothing meaningfully exists. Time itself is just another word for difference - each moment is distinct from the last.
When things change, some persist and others don’t.
A rock endures through many states; a soap bubble vanishes. This persistence creates what Bennett calls the “cosmic ought” - the universe inherently selects for self-preserving structures. This foundational normativity cascades upward through all levels of organization.
The Cosmic Ought
The universe preserves things that preserve themselves. This isn’t conscious selection - it’s simply that things that don’t preserve themselves aren’t around anymore. This creates a fundamental normativity: some things ought to exist (because they persist), others don’t.
Valence as Universal Currency
At its core, everything that persists must be attracted to states that preserve it and repelled by states that destroy it. Even a chemical molecule “moves” toward stable configurations. This basic attraction/repulsion - valence - is the universal currency from which all experience emerges.
A natural tendency towards conservatism / self-preservation. But the only way to persist is to embrace constant change.
What’s Life?
As systems grow complex, they form abstraction layers - atoms form molecules, molecules form cells, cells form organs. Each layer interprets the one below, like software running on hardware running on physics.
In biological systems, each layer can adapt, unlike the rigid stacks of computers.
Tapestries of Valence - The Emergence of Quality
When millions of simple units network together, their collective patterns of attraction and repulsion create rich “tapestries of valence.” What we call qualia - the redness of red, the pain of pain - are these complex patterns.
Red isn’t a neutral label we attach feelings to; it’s a specific tapestry of attraction and repulsion across our sensory system. When you see food, you don’t first neutrally identify “food object” and then apply “positive value” - the recognition itself is attractive. The tapestry of valence that recognizes food is simultaneously the pull toward it.
Reward is not a label applied after the fact. Interpretation and value judgement are one and the same.
The system doesn’t recognize something then evaluate it; the recognition itself is evaluative.
We don’t need to explain how neutral representations acquire subjective character - there are no neutral representations. Everything is made of valence from the ground up.
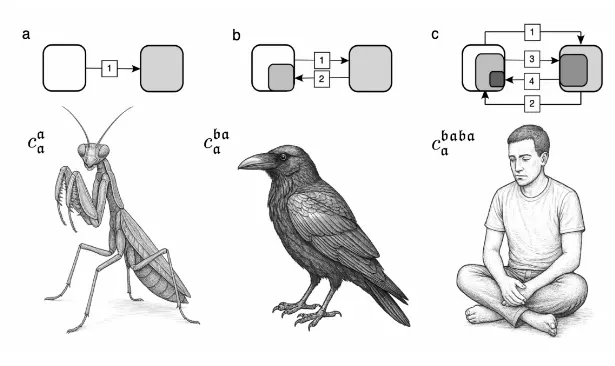
Three Orders of self
1st-order self: Distinguishes “what I caused” from “what happened”
2nd-order self: Models what others think of me
3rd-order self: Awareness of self-awarenessTo navigate effectively, any mobile system must distinguish changes it caused from changes that just happened. This requires constructing a 1st-order self - a causal identity for one’s own interventions. This self accompanies every action, giving behavior a unified character. This is “what it’s like” to be that system. Even a fly must have a 1st-order self.
When systems need to predict other systems, they develop 2nd-order selves - models of how others model them. This isn’t just useful for hunting or escape; it’s the foundation of meaningful communication. To convey meaning in Grice’s sense, I must predict what you’ll think I’m thinking. Only information within these 2nd-order selves is available for what we call “access consciousness”.
With a 3rd-order self, systems gain awareness of their own self-awareness. This enables complex social reasoning - planning interactions where multiple parties predict each other’s responses. It’s where sophisticated deception becomes possible, as I can reason about your prediction of my intended meaning. This creates the “impelling narrative” of human consciousness - when we plan future interactions, we partially experience the anticipated feelings and sensations. This internal screenplay, where imagined futures carry emotional weight, may be unique to humans and perhaps a few other species.
Simultaneous Nested Selves
The orders of self aren’t separate entities but nested levels of abstraction in the same system. Like Russian dolls, each higher order contains and depends on the lower ones. You can’t have a 2nd-order self without a 1st-order self actively operating beneath it.
From Bennett’s description, the 1st-order self is always active - it’s the continuous tapestry of valence that accompanies every action you take. It’s your basic phenomenal experience, always running in the background.
The 2nd-order selves are contextually activated based on your surroundings:
“attention is whatever is in the 2ND-order-selves I am predicting given my current surroundings”
So while you have many potential 2nd-order selves (one for each person/context you might model), only relevant ones are active at any given moment.
The 3rd-order self enables the internal narrative - it’s constantly running scenarios, planning interactions, creating that inner screenplay of consciousness.
Upward vs Downward Access / Communication between levels
Higher orders can access lower ones because they’re built from those lower orders.
But lower orders can’t access higher ones because they lack the representational machinery to do so.
The 2nd order can and must access the 1st order because:
It’s built on top of it - The 2nd-order self is essentially predicting how others see your 1st-order self
Quality persists upward - Bennett emphasizes that tapestries of valence (the feeling/quality) carry through: “second order selves… must have quality if learned through phenomenal conscious”
Integrated representation - There’s no separation between representation and valence, so the 2nd order inherently includes the 1st order’s qualities
This explains why you can be consciously aware of your feelings (2nd accessing 1st) but your raw feelings can’t independently reason about social dynamics (1st can’t access 2nd). The communication is essentially one-way upward inclusion rather than bidirectional exchange.
Why Consciousness Exists - Consciousness is not an accident or epiphenomenon
… it’s the most efficient solution to the problem of adaptation in complex environments.
A philosophical zombie would be less efficient than a genuinely conscious being because consciousness provides exactly the kind of integrated, flexible, self-modeling system needed for optimal adaptation.
→ Consciousness and intelligence are fundamentally linked - you can’t have one without the other.
Consciousness emerges naturally from the need for efficient adaptation in complex environments.
See also Consciousness as a coherence-inducing operator - Consciousness is virtual
I also see many parallels to the NOW model (tho I still haven’t read the paper yet, have only watched the talk :/, and it’s been some while).
The Weakness Principle
W-maxing (Weakness Maximization)
Optimal adaptation requires choosing the weakest correct hypothesis - the one that constrains future behavior the least while still being correct.
Weakness = size of hypothesis extension (how many possible futures it allows)
Simplicity = brevity of description (occam’s razor)Bennett proves weakness is necessary and sufficient for optimal learning
Occam’s Razor Fails: Simplicity is neither necessary nor sufficient for generalization.
In the experiments, sometimes the weakest hypothesis was complex, sometimes the simplest hypothesis was overly specific.
Weakness always won.
Why does simplicity seem to work? Because finite space forces a correlation
The universe has spatial limits → finite vocabularies → to fit useful patterns, weak constraints often take simple forms.
But this is correlation, not causation! Simplicity doesn’t cause generalization - weakness does.
Simplicity is just a side effect when space is limited.
The Experiments
Bennett tested learning binary arithmetic with limited examples:
Training Examples W-maxing Success Simplicity Success 6 11% 10% 10 27% 13% 14 68% 24% W-maxing showed 110-500% better generalization - choosing general patterns beats choosing simple ones.
Swiss Army Knife vs Scalpel
Weak hypothesis: “Things bounce” (applies many situations)
Strong hypothesis: “Balls bounce exactly 5.2 inches on Tuesdays” (very specific)The weak hypothesis is like a Swiss Army knife - less precise but useful everywhere. When you have limited data, betting on generality beats betting on simplicity.
As tasks get harder (or more numerous), fewer hypotheses fit → eventually only one remains. We can skip straight to choosing the weakest hypothesis rather than waiting for data to force convergence
It’s like solving a general problem that includes your specific case - often easier than solving just the specific case!
Takeaway
For AI: Stop optimizing for compression/simplicity. Optimize for generality.
For Biology: Life looks complex because general solutions need complex implementations in finite space
For Science: We should prefer theories that constrain least while still explaining phenomena
Building Conscious Machines
Must consciousness exist at a single point in time, or can it be "smeared" across time? (→ can sequential processing systems be conscious?)
It seems as if consciousness is a pattern through time, something that only manifests as time progresses, with our self-reflective / higher order self-awareness operating on top of these bubbles of now, which integrate sensory information, prediction, and memories into a coherent experience.
To build a conscious machine, Bennett argues we need systems that delegate adaptation all the way down their stack - unlike current computers where only the top layer (the model parameters) can adapt:
Current AI systems are fundamentally limited because they don't delegate adaptation to low enough levels. A GPT model can adjust its parameters, but the Python interpreter, the operating system, and the silicon can't adapt to better support the task.
I agree adaptivity is required, but I’m not sure we really have to go this low… as long as we can simulate similar adaptive processes, albeit at the expense of efficiency?
The Missing Tapestry
LLMs process information sequentially - they judge and represent information separately. 1 There’s no “tapestry of valence” where representation and evaluation are unified.
When LLMs process “user wants X,” it’s a neutral label, not an integrated attractive/repulsive force. (is it tho? what about circuits & iCL? are there no dynamics introduced through RL? This example seems clearer: The representation of “food” in an LLM doesn’t hunger - it’s just inert data waiting to be processed. Hm, but doesn’t it also shift the attention / relate to the context / activate new features? But I suppose 1) from the points below is convincing enough)
The key architectural differences:
No 1st-order self: LLMs can’t distinguish “what I generated” from “what was in my training.” They have no reafference - no causal identity for their own interventions.
Sequential, not synchronized:
“A single core CPU is like a distributed system with only one part, passing messages asynchronously to future versions of itself”
Even with parallel hardware, the actual reasoning is smeared across time rather than realized as a synchronized state.
Top-down only: Everything in an LLM is imposed from above - the architecture, training objective, prompting. There’s no bottom-up emergence from lower levels adapting independently.
An LLM might output text that looks like it’s modeling your intent, but we’re imposing our interpretation on mechanical constraints – we see intelligent behavior and assume understanding. It’s behaviorally similar but phenomenologically empty. “We constrain LLMs with training data and architectures until they can only produce human-like text”, like water finding the only available path downhill.
"We have foolishly treated representations as platonic. We have treated goals and representations as independent, when they are not."
Bennett suggests LLMs construct “halls of mirrors” instead of unified models:
“They can cope with arithmetic using short numbers, but fail when given long numbers. This suggests they construct many incomplete representations… but fail to synthesize a solitary and sufficiently weak interpretation”
Compression may correlate with intelligence, as in task-specific skills, but general intelligence requires picking up new skills efficiently.
Requirements for True 2nd-Order Selves
Bennett proposes we’d need:
- Different hardware: “self-organizing nanomaterials that can physically reconfigure themselves rather than static silicon”
- Bottom-up architecture: Where lower levels can adapt independently, not just top-level parameter tuning
- Integrated valence: Representation and evaluation as one unified process, not separate steps
- Synchronous realization: The entire self-model realized at a point in time, not smeared across sequential processing
why does he argue for different hardware being necessary? simulation too inefiicient?
References
artificial intelligence, emergence
Read (or rather listen to … once yapit is done) the book manually; take notes on mathematical details
Footnotes
-
In an LLM, the process looks like: Represent: “The user said X” → encoded as embeddings/tokens Store: These representations sit in memory as neutral data Judge: Apply attention weights, calculate probabilities Evaluate: Determine next token based on learned patterns ↩