year: 2022/05
paper: https://arxiv.org/abs/2205.14953
website: https://www.reddit.com/r/MachineLearning/comments/v2af3k/r_multiagent_reinforcement_learning_can_now_be/ | https://sites.google.com/view/multi-agent-transformer
code: https://github.com/PKU-MARL/Multi-Agent-Transformer
connections: MARL, transformer
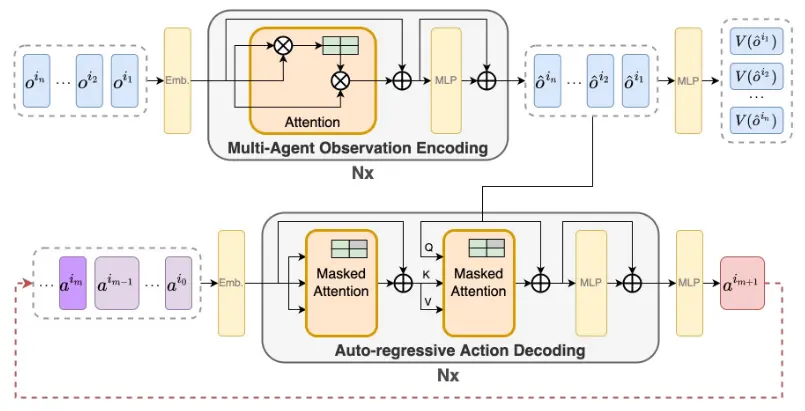
Note how Q comes from the encoder, which is a non-standard way to do cross-attention.
There are no notes about any architectural details in the paper, though maybe this inversion shifts focus from “what context is relevant for the next token?” (NLP) to “what action should follow given the global state and prior actions?” (MARL).
Preliminaries
Multi-Agent Observation-Value Functions
The multi-agent observation-value function measures the expected return starting from observation when a subset of agents execute specified actions and all other agents execute actions according to their current policy .
Building on this, for disjoint ordered subsets of agents and , the multi-agent advantage function measures the relative benefit of agents taking specific actions after agents have committed to actions :The advantage is positive if the chosen actions lead to better expected returns than letting those agents follow their default policy behavior, given the actions already chosen by agents .
Example
Consider a team of 3 agents where:
Agent 1 commits to action first () and we want to evaluate the advantage of agents 2 and 3’s joint action ()
The advantage function would measure how much better/worse agents 2 and 3’s chosen actions are compared to the expected value after only agent 1’s action and following the policy of agents 2 and 3.
Link to originalMulti-Agent Advantage Decomposition Theorem
Let be a permutation of agents. For any joint observation and joint action :
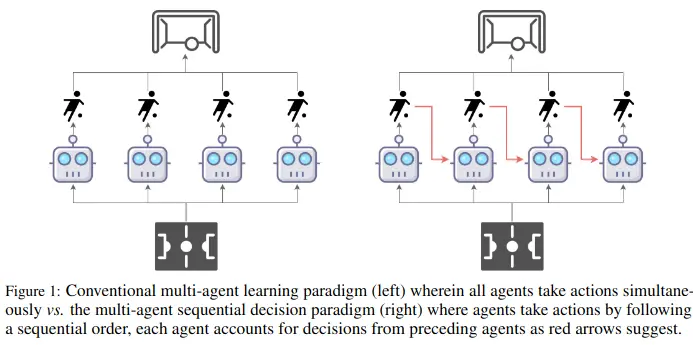
The total advantage of a joint action can be decomposed into a sum of individual advantages, where each agent’s advantage is conditioned on the actions chosen by previous agents in the permutation.
This enables sequential decision making.
Agent goes first, picks an action with aiming for positive advantage
Agent , knowing , chooses for positive
Agent , knowing , …Instead of searching the entire joint action space , we can search each agent’s action space separately .
→ Each agent can make decisions based information about what others have done, incrementally improving actions.
→ The computational savings get more dramatic as you add more agents
Link to originalMAPPO objective
The objective of MAPPO is equivalent to that of PPO, but equipping each agent with one shared set of parameters, i.e. . It uses the agent’s combined trajectories for the shared policy’s update.
So the objective for optimizing the policy parameters at iteration is:The constraint on the joint policy space imposed by shared parameters can lead to an exponentially-worse sub-optimal outcome (details; page 4).
Link to originalHAPPO vs MAPPO
MAPPO is a straightforward application of PPO to multi-agent settings, often forcing all agents to share one set of policy parameters. This can be suboptimal when agents need different behaviors.
HAPPO relaxes this constraint by:
- Sequentially updating each agent in a random permutation , where agent updates using the newly updated policies of agents .
- Leveraging the Multi-Agent Advantage Decomposition Theorem, which yields a valid trust‐region update for each agent’s local advantage . Specifically, HAPPO applies the standard PPO (clipped) objective to each agent while treating previously updated agents’ policies as “fixed.” Because the decomposition theorem ensures the local advantage aligns with the global return, any PPO‐style step that respects the trust region (i.e., doesn’t deviate too far from the old policy) guarantees a monotonic improvement for the entire multi-agent policy.
- Maintaining distinct policy parameters for truly heterogeneous capabilities.
This ensures a monotonic improvement guarantee for the joint return – something MAPPO’s parameter-sharing approach can’t guarantee. As a result, HAPPO typically performs better than MAPPO in scenarios where agents must learn different skillsets.
However, one drawback of HAPPO is that agent’s policies has to follow the sequential update scheme (in the permutation), thus it cannot be run in parallel.
Implementation
Algorithm
Steps:
- Generate encoded joint agents observations:
- Generate state-value estimates from observations:
- Autoregressively decode agent actions, while cross-attending the encoded observations:
Slap PPO on top… that’s it!
