self-attention, but the keys and values come from a different source, not from the same input.
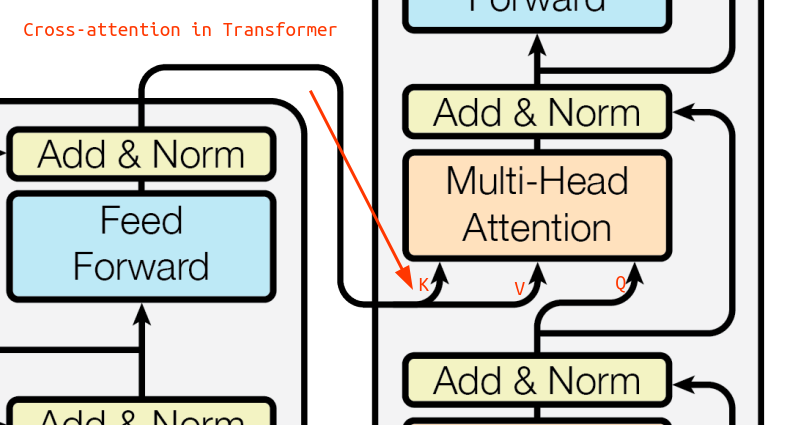
Cross-Attention
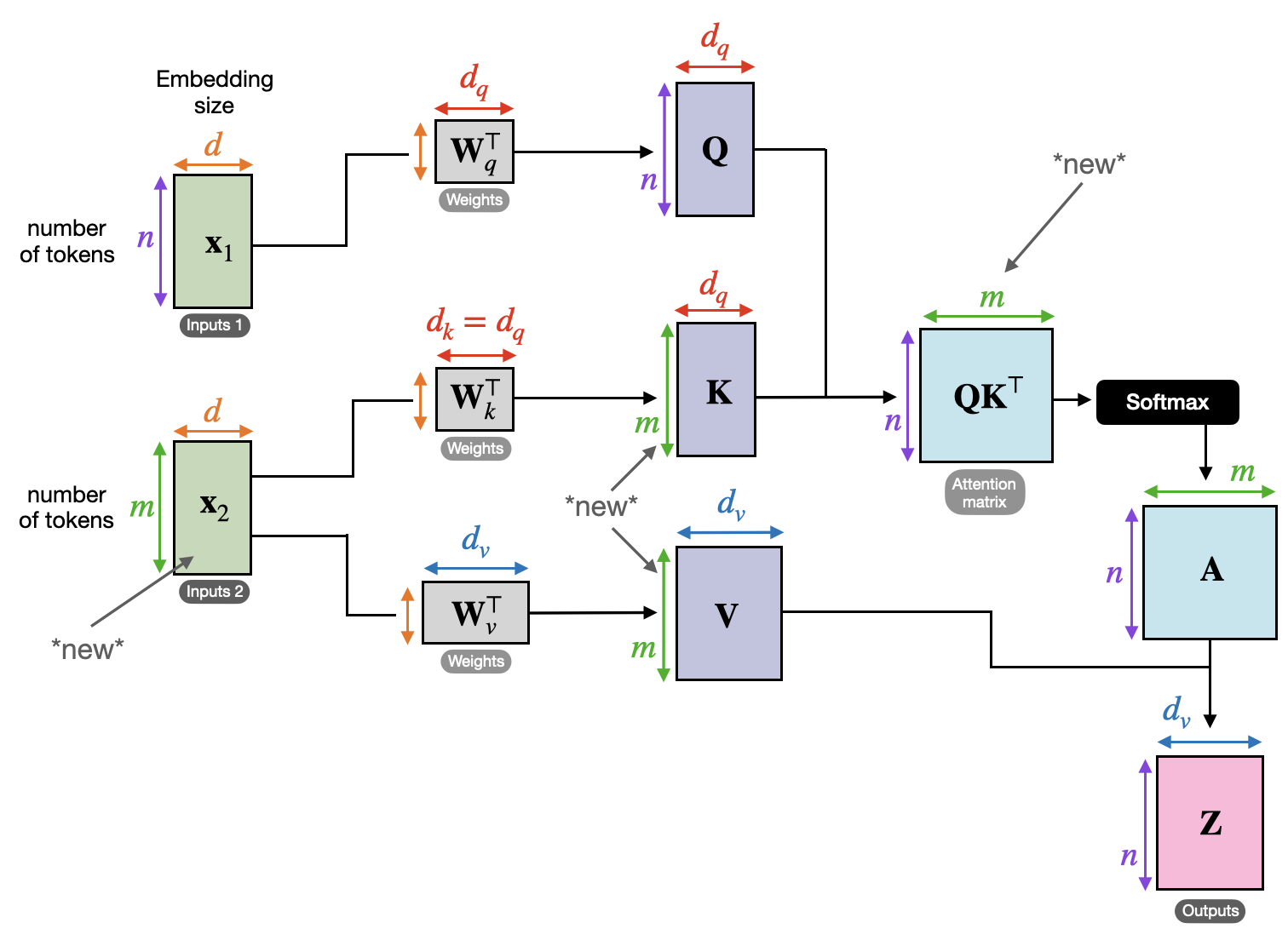
Queries correspond to the rows of the attention matrix.
Keys correspond to the columns of the attention matrix.Note: Neither the number of tokens nor the dimension of the two “modalities” need to match up. Hower in practice they often do (we use a single
d_model, as in the image above).
HuggingFaceDiffusers code
Cross-Attention in Transformer Architecture (also stable diff, …)