go through this in ~december
Motivation
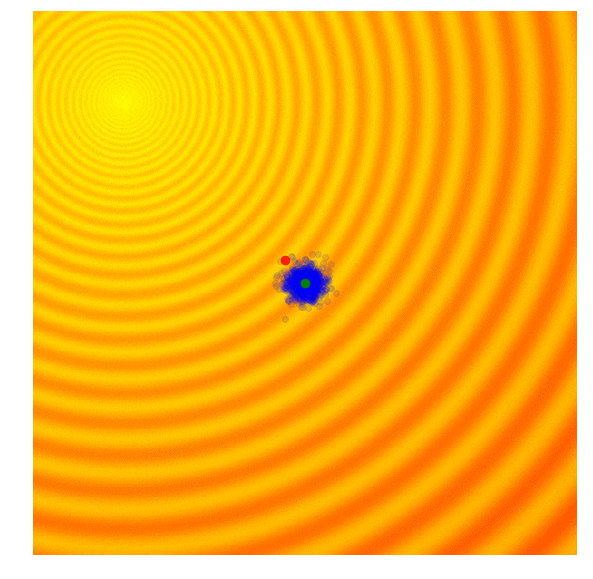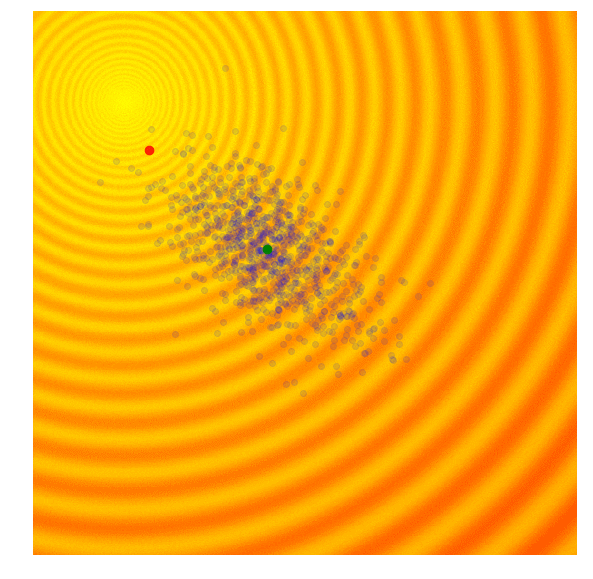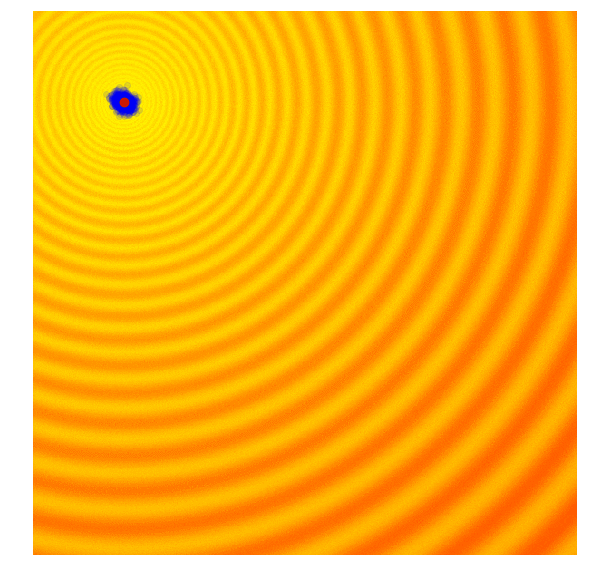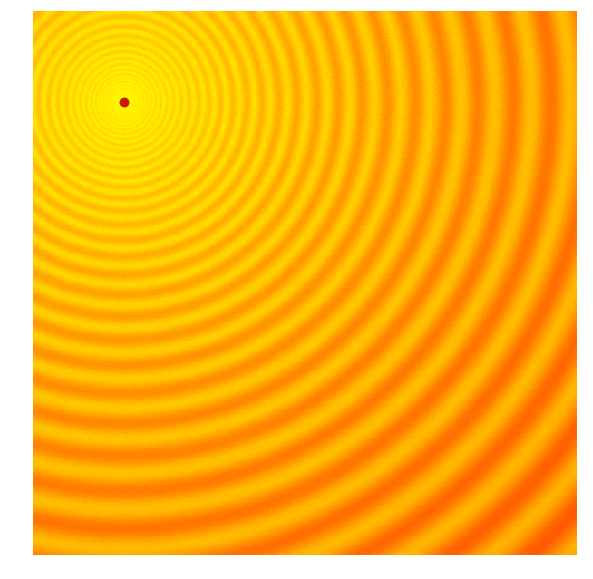
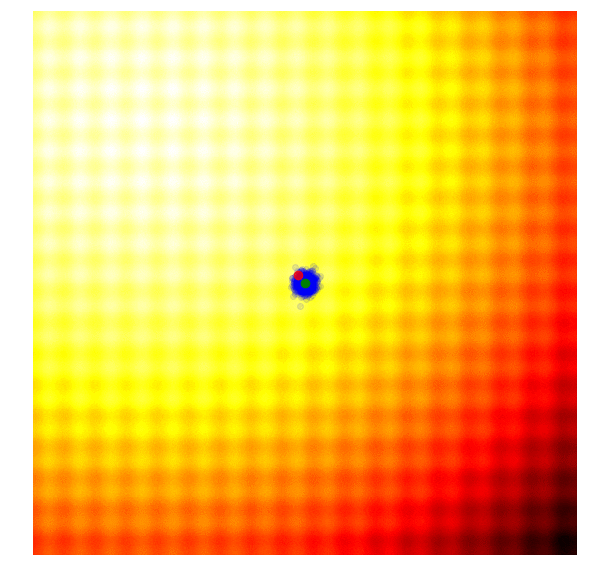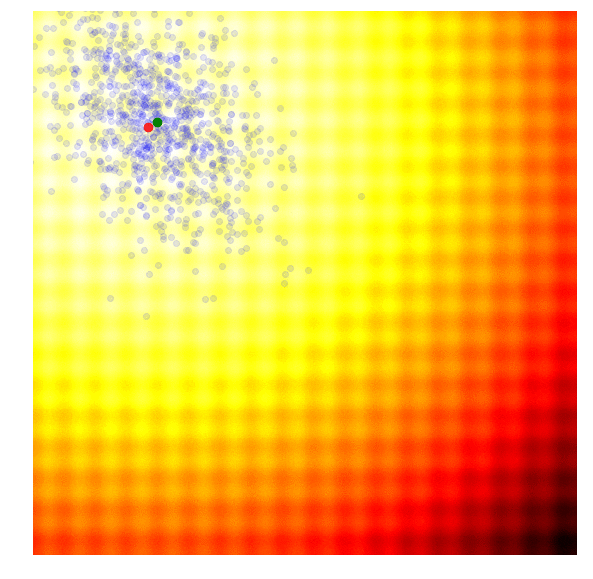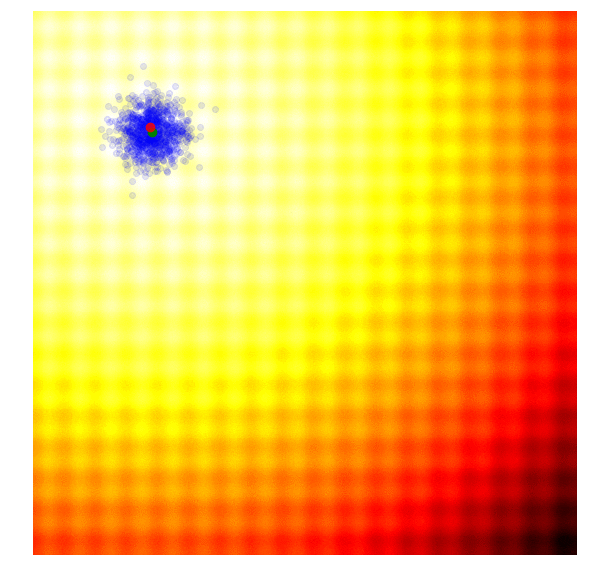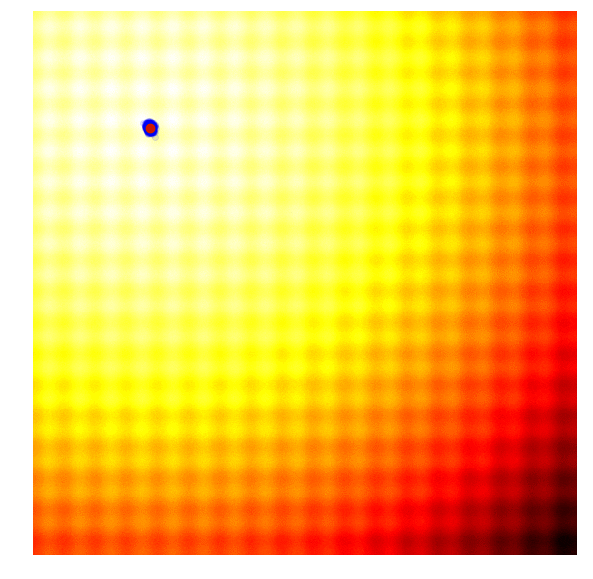
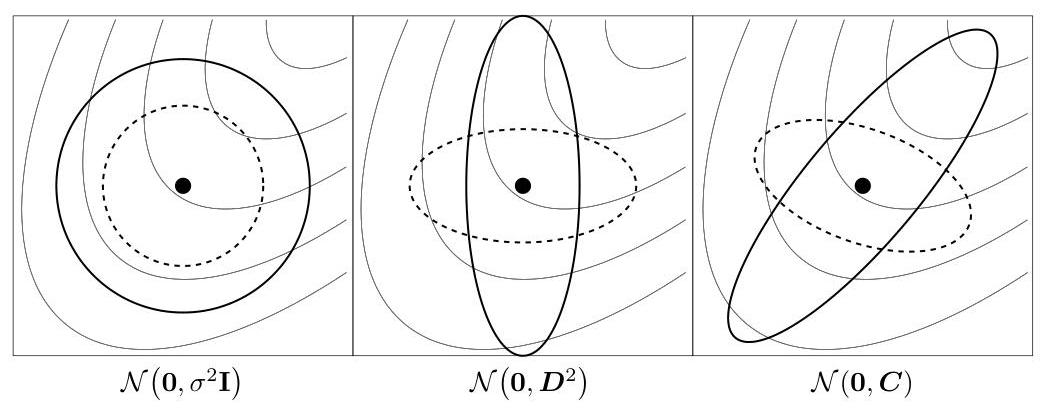
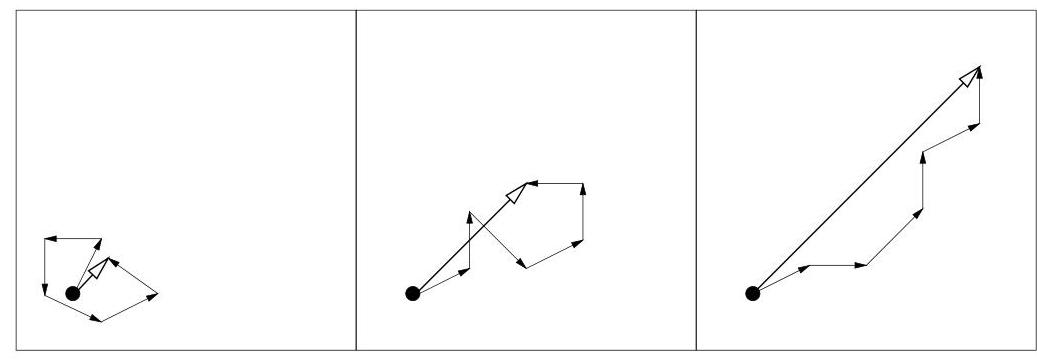
CMA-ES
CMA-ES biases the search/distribution towards the direction of the elite, and adapts it depending on whether the best solutions are far away or close by, in addition to updating the mean of the distribution towards the elite.

Naive covariance matrix adaptation
We could try to naively adapt the covariance matrix of the current population, but instead of calculating w.r.t.t. mean of the entire population, we calculate w.r.t.t. mean of the elites.
But that alone is not enough. This way alone the distribution gets stretched very thin in the direction of the elites, and the size of the distribution shrinks quickly, because if the distribution is a long ellipse, the new population will be spread out along that axis too, and if it shrinks, the elite will be closer to the mean, the distribution shrinks even more, …

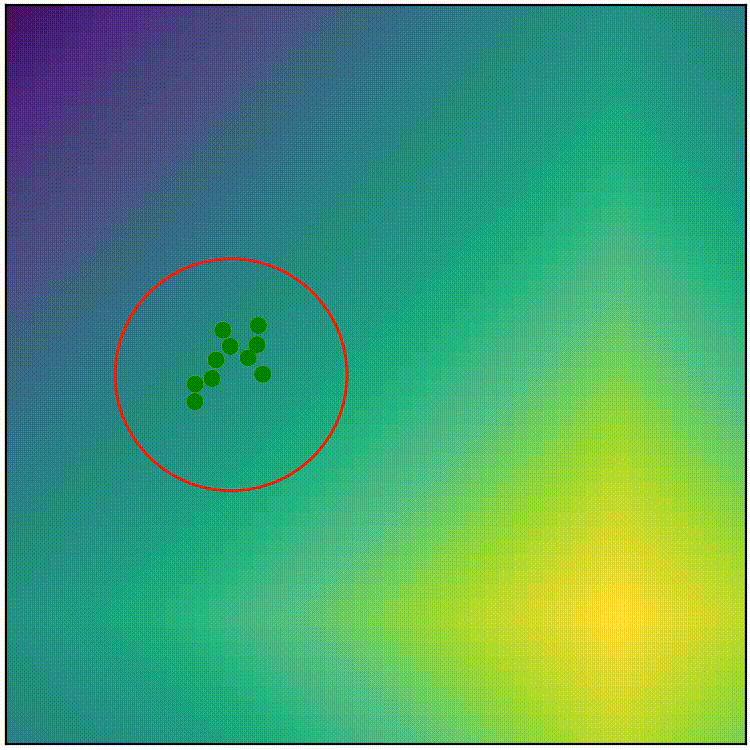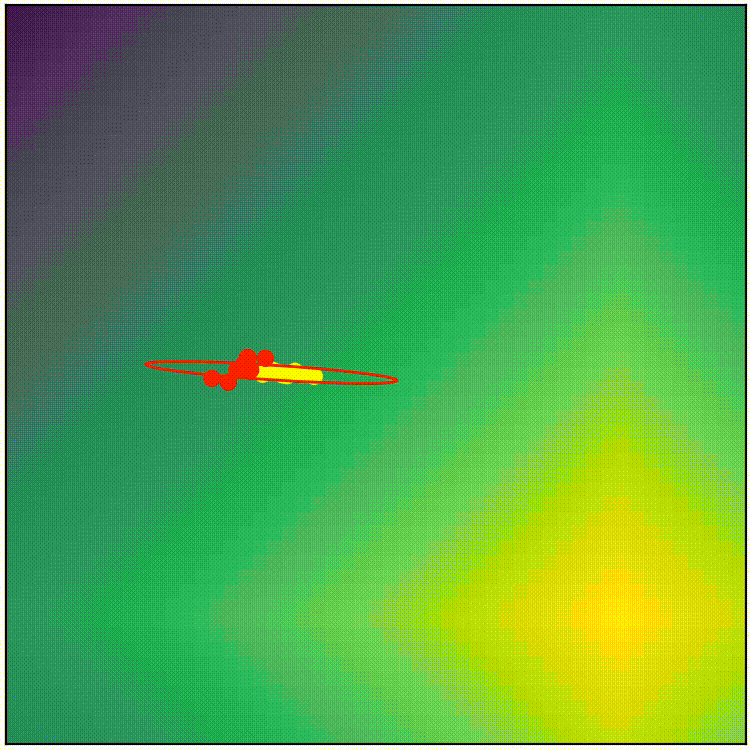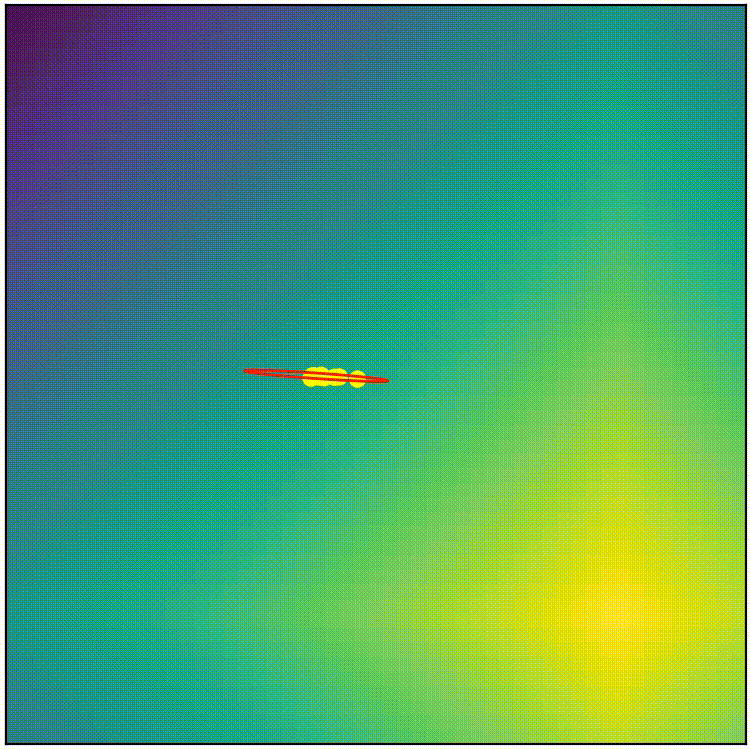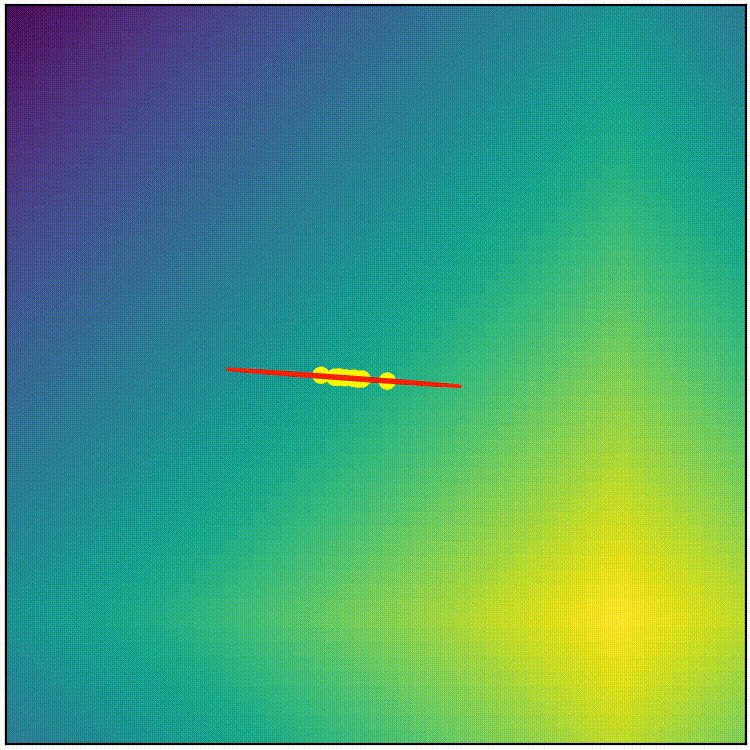
Line 1: Affine property of gaussian
Line 2: is the matrix square root of
Line 3: eigendecomposition of
Line 4: since is a orthogonal matrix and rotations of a standard normal distribution are still standard normal (rotating a sphere).
Since the covariance calculation scales with , cma-es starts becoming unpractical for > ~10k parameters, but low-rank approximations, for example: LM-MA-ES or sep-CMA-ES
covariance matrix evolution strategies
CMA-ES YouTube series + blog:
https://szhaovas.github.io/2023-02-06-cmaesall/
https://szhaovas.github.io/2022-09-06-cmaes/
https://szhaovas.github.io/2022-09-07-cmaes2/
https://szhaovas.github.io/2022-09-09-cmaes3/
https://inria.hal.science/hal-00808450v1/document