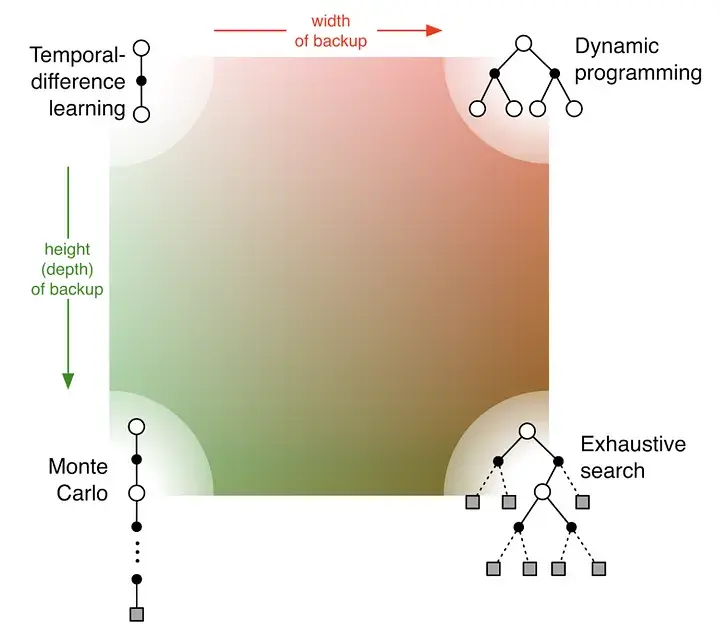
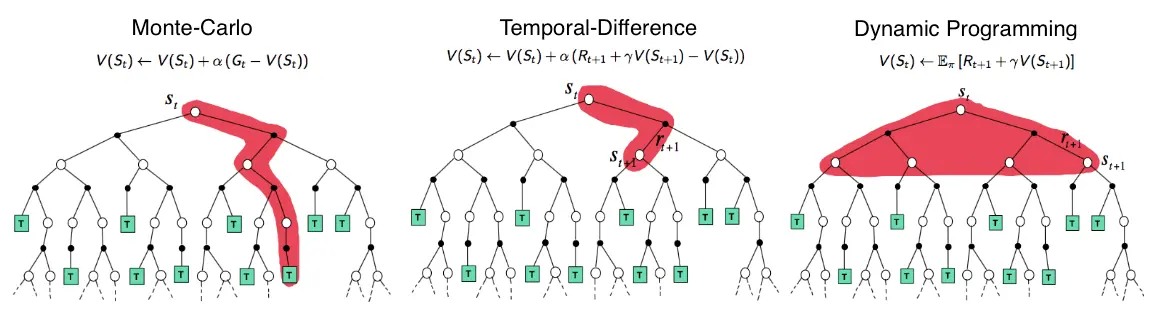
Link to originalThe picture shows the value propagation (“backup”) of a single update step with these three methods:
MC methods require complete episodes to learn, using actual returns to update value estimates. They’re unbiased (as long as there is exploration) but have high variance and require complete episodes (and thus more samples to achieve an accurate estimate, so bad for expensive environments), though truncated returns can also work.
TD bootstraps from existing value estimates after single steps, combining actual rewards with predicted future values. This introduces bias but reduces variance and enables online learning.
DP methods use the full model of the environment to consider all possible next states simultaneously, computing expected values directly. This is most sample-efficient (you don’t need to sample in order to approximate values – at the cost of exhaustive search) but requires a complete model of the environment, and are impractical for large state spaces, even with a perfect model (curse of dimensionality).
MC (left) vs TD
https://lilianweng.github.io/posts/2018-02-19-rl-overview/#monte-carlo-methods