Rather than only computing the attention once, the multi-head mechanism applies the self-attention attention mechanism multiple times in parallel, each with its own set of weights.
-20240807155114439.webp)
Why multiple heads?
multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions. With a single attention head, averaging inhibits this.
In plain english:
Intuitively, having multiple attention heads allows for attending to parts of the sequence differently (e.g. longer-term dependencies versus shorter-term dependencies).
The softmax from the scaled dot product attention strongly tends to focus on a single element. Hence multiple heads are useful. They allow to consider many possible interpretations of a sequence, all in one feed-forward pass.
Communication is followed by computation ( self-attention → MLP).
Since we get n outputs (8 in paper) they need to be concatenated and is multiplied by yet another weight matrix (Linear Layer) to obtain the shape of a single output. Each head’s output features are kept together: if each head outputs features, the concatenated output has head 1’s features in positions , head 2’s in , etc.
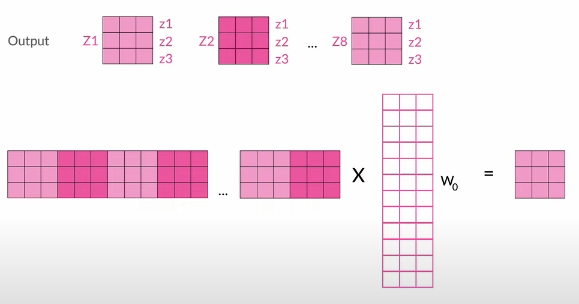
MHA is permutation equivariant (without positional encodings)
One crucial characteristic of the multi-head attention is that it is permutation-equivariant with respect to its inputs. This means that if we switch two input elements in the sequence, e.g. (neglecting the batch dimension for now), the output is exactly the same besides the elements 1 and 2 switched. Hence, the multi-head attention is actually looking at the input not as a sequence, but as a set of elements.
If the order / position of inputs is important for solving the task (language, vision, …) you encode position in input. (Positional encodings)
The different heads eventually communicate with eachother in the dot product calculation
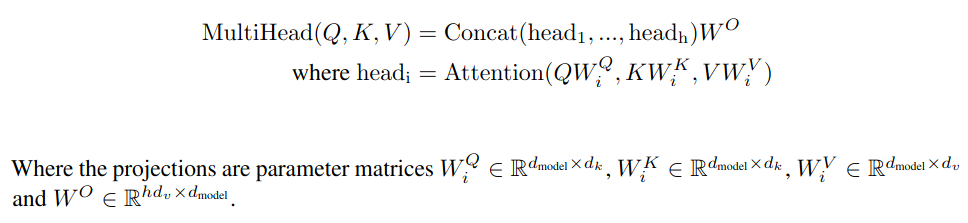
Implementation
MHA forward pass with einops

Full example
Transclude of einops#^64c38b