Tldr of trenton's PHD thesis
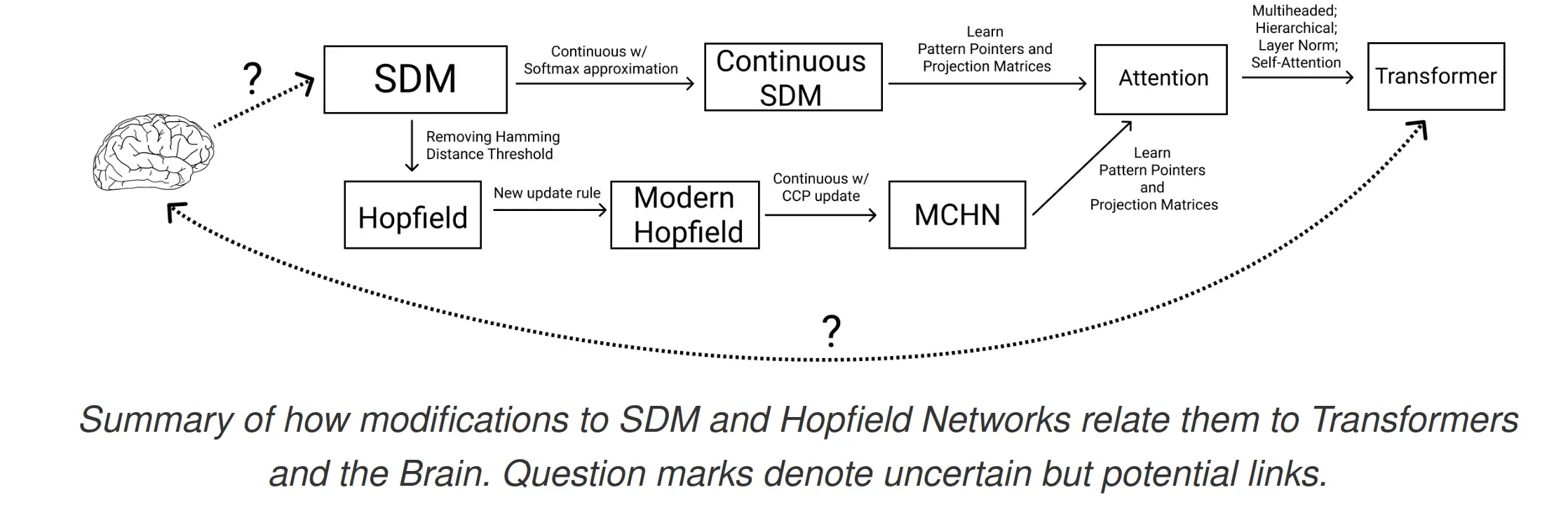
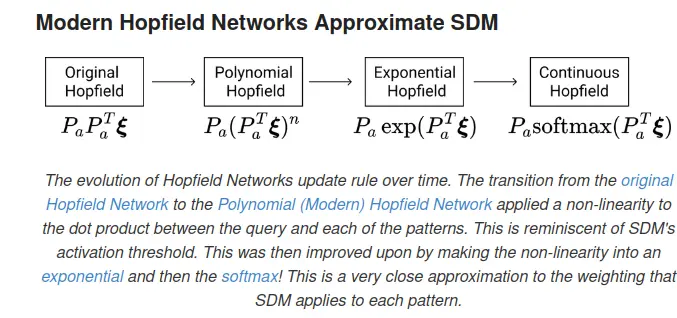
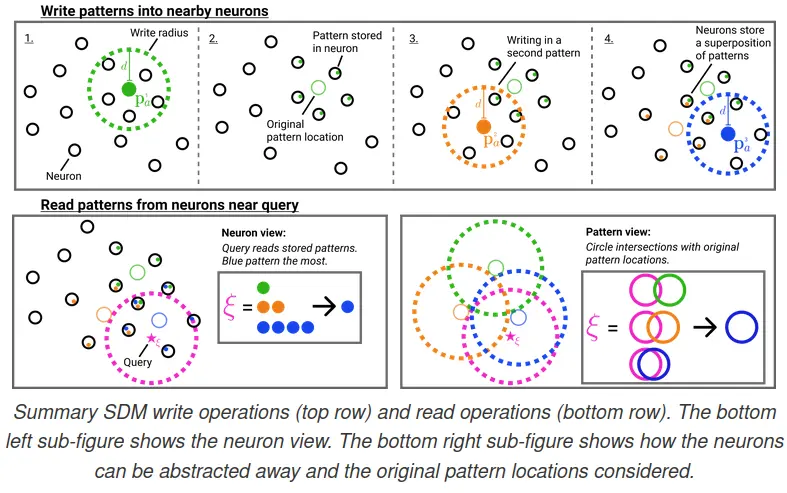
Attention ≈ Sparse Distributed Memory (SDM): Shows that transformer attention is mathematically equivalent to Kanerva’s SDM — a neuroscience-inspired associative memory model from the 1980s. The softmax attention weights approximate the “circle intersection” weighting that SDM uses. This gives a biologically plausible story for why attention works.
SDM for continual learning: Uses SDM principles (sparse, high-dimensional representations with localized writes) to build MLPs that avoid catastrophic forgetting. Inspired by cerebellar architecture. The sparse activation pattern means new learning doesn’t overwrite old memories as much.
Noise → Sparsity: Training with noise (like dropout, but on activations) naturally induces sparse representations. Networks learn to push neurons below the ReLU threshold most of the time, then “jump” to high activations when genuinely needed. Also produces Gabor-filter-like receptive fields spontaneously. Offers a potential explanation for why biological neurons are sparse.
Sparse Autoencoders for Interpretability: This is the Anthropic “Towards Monosemanticity” paper. Uses dictionary learning to decompose LLM activations into interpretable sparse features, addressing superposition (where models pack many concepts into fewer dimensions). Shows you can extract clean features like “Arabic text” or “DNA sequences” that are more interpretable than individual neurons.→ Sparse codes are good for memory capacity, continual learning, noise robustness, and interpretability.