This note is mostly from long ago, so for a higher quality intro, refer to https://lilianweng.github.io/posts/2018-02-19-rl-overview/ or steve brunton’s playlist (this note is not based on these) or the various, newer, topical notes. Though this does cover some basics which I don’t mention in any other note. I also shifted some stuff to RL.
An agent learns and takes actions at each moment in time: .
The action is received by the environment which gives a reward and state at the next moment in time () → Passed back to agent to decide next acition.
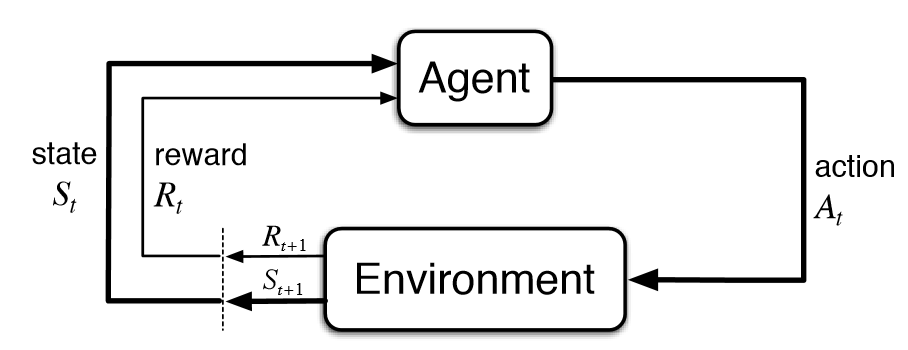
form a Finite Markov Decision Process.
Note
Uppercase indicates random variabes.
Lowercase indicates values they can take.
(=discrete)
(finite set of anything)
(set of actions we can take depends on the state we are in)
(finite subset of real number line; e.g. )
is a complete description of the “world”, while and observation is a partial description of a state.
The dynamics of the agent / env interaction is specified by this distribution function
… gives the probability of the next state and reward, given the current state and some action to be taken.
Link to originalMarkov property
The probability of the next state and reward only depends on the current state and action.
The reward does not depend on the history of states and actions.Stationary dynamics: and are fixed functions. The environment is assumed to be fixed.
The agents behaviour is given by the policy:
The policy gives the probability distribution over actions in a given state.
The agent samples randomly from this distribution (=stochastic).
If only one action can be taken from each state, the policy is deterministic:
In deep RL, the parameters of the network are also mentioned in the notation
This means the action at time is determined by applying the policy or , which is determined by the weights of the network .
Action spaces are the set of actions an agent can take. They can be either discrete (like in chess) or continous (robots in the real world) → real-valued vectors.
Not all deep RL methods work for both cases.
A trajectory is a sequence of states and actions in the world:
(also called episode or rollout)
The very first state of the world is randomly sampled from the start-state distribution, sometimes denoted by :
In normal chess, is deterministc.
State transitions can be either deterministic,
or stochastic,
The reward depends on the current and next state and the action taken:
Frequently it is simplified to just depend to the dependence on the current state, , or state-action pair, .
The goal of the agent is to maximize some notion of cumulative reward (return) over a trajectory, but this can actually mean a few things.
The simplest kind of return is the finite-horizon undiscounted return:
… the sum of rewards in a fixed window of steps.
The infinite-horizon discounted return is the sum of all rewards ever obtained by the agent, but rewards are discounted by how far off in the future they are obtained:
Smaller early rewards are more important.
Intuitively, it is better to have rewards right away than having to wait for them.
Mathematical reason: An infinite-horizon sum of rewards may not converge to a finite value (could just get higher and higher) → hard to deal with in equations. With , the infinite sum converges.
Note
While the line between these two formulations of return are quite stark in RL formalism, deep RL practice tends to blur the line a fair bit—for instance, we frequently set up algorithms to optimize the undiscounted return, but use discount factors in estimating value functions.
So our goal is to maxmize the expected return. For that, we need the probability of the different trajectories.
In the case of a stochastic policy and environment, the probability(distribution) of a -step long trajectory (state action sequence) under a given policy look like this:
… multiply the initial state distribution with the sequence of distributions over actions and states.
Then the exptected return (for whichever measure) is:
… we sum over the probability of all possible trajectories times the respective reward (integral due to continous case).
In practice, we can’t calculate all trajectories, so we sample a subset from . That’s also where Monte Carlo methods come into play.
The central optimization problem in RL can then be expressed by:
… optimal policy
… for which policy does achieve the highest value? The returns the actual policy, rather than the max value itself.
We end up with the policy of the highest average return.
Value Functions tell us the complete future value (expected return) of a state / state action pair, provided that we act according to a particular policy forever after. They are used in almost every RL algorithm.
On-Policy Value Function (a state value function):
… gives the expectation of the return, given the agent starts at state and always acts according to the policy afterwards.
Same as the goal function, the thing we optimize for, but broken down by state. tells us how good it is to be in some state.
Breaking it down even further with the On-Policy Action-Value Function:
… expectation of the return, given the agent starts at state , takes an arbitrary action action (doesn’t need to be from the policy), and
always follows the policy afterwards. tells us which action to take.
With these two functions we want to find the optimal policy .
A policy is optimal, if it achieves the highest possible expected return for all states:
There is always at least one optimal policy.
Abbrev. notation for optimal policies: or .
Dynamic Programming
Refers to algorithms used to find optimal policies which have complete knowledge of the environment as an Markov decision process → The dynamic program has access to:
Another way of formulating it is by writing down the Optimal Value Function and the Optimal Action-Value Function:
… we start at state (+ take action ) and then act according to the optimal policy forever after.
The optimal policy gives us the optimal action:
There may be multiple actions that maximize the return but there is also always one which deterministically selects the optimal action.
The and the function don’t just look simmilar, they also have a nice relation to eachother:
… the value of a state if you act according to a policy is the average / expected action value of that policy in that state.
… the optimal value of a state is the maximum action value that can be optained from a state.
Bellman Equations / Q-learning
What the functions tell us, are not just the immediate reward that I get in the state or the immediate reward following an action, but the likelihood of ending up in a good / bad state after taking some action / being in some state is also accounted for.
So the reward is the reward I get right now (might be nothing until the terminal state like in chess, or might be huge even though end-goal is not reached) and the sum of the following rewards (=return), following recursively, discounted:
The basic idea of the Bellman Equation is:
If the function can give me an estimate of the reward for a function, why don’t I always ask it, rather than the policy? →
Here is where the recursion comes into play:
What shall I do right now, If I also intend to follow this function in the future.
More formal way of noting down the Bellman Equations:
where is shorthand for , indicating that the next state is sampled from the environment’s transition rules; is shorthand for ; and is shorthand for .
Now we know that the function tells us what a good state is, and that we can use it as our policy, but how do we learn a good function?
We start off with with a function (neural net with parameters ), that doesn’t know anything about what a good state is or not, it has a random estimate of the reward.
This neural network then maps from the input state to a distribution over actions (in the discrete case).
It can also encode the action as input and then have just a single output. This has some drawbacks however, like having to do a separate forward pass for each action → cost scales linearly with the number of actions.
The total current reward of the net is the actual reward at the current step + the estimated reward for the future (sloppy notation):
Or we can rearrange to:
\begin{align} r_t = Q_\theta(s) - Q_ \underset{ \text{fixed} }{ \theta } (s') \end{align}So the reward for any step is the difference between the Q-function of this and the next step. Q-learning is thus a form of temporal difference learning. We have a fixed set of predictions, which we update every steps (for stability reasons) with the weights of a second net which learns from new experiences.
In short: The model improves by going through episodes (irl randomly sampled experiences from episodes) and comparing its reward estimates with the actual rewards
was temed a Deep Q Network in the Atari paper which kickstarted Deepmind in 2013.
The delayed update of the target network might seem counter-intuitive but it has advantages of:
- Stabilizing the training by reducing the variance in gradient updates
- Improving generalization trough preventing overfitting on recent experiences
The update can be hard by replacing the target weights by the policy weights or it could be soft, continously nudging the target weights by some factor.
References
Some sources
https://spinningup.openai.com/en/latest/spinningup/rl_intro.html
https://youtu.be/NFo9v_yKQXA?list=PLzvYlJMoZ02Dxtwe-MmH4nOB5jYlMGBjr