Types of normalization techniques in machine learning - comparison
Link to original
Input: Values of over a mini-batch:
// mini batch mean
// mini-batch variance
// normalize
… noise parameter in case variance is 0 (div by 0)
Since mean and variance are heavily dependent on the batch, we introduce learnable parameters (unit gaussion at initialization but optimization might change that).
(scale) approximates the true variance of the neuron activation and
(offset) apporximates the true mean of the neuron activation.
Usually placed after layer that have multiplications (Linear, Conv, …)
You want to center your data, and normalize the data (rescale the axes) so they are more like gaussians > signal propagates better
(+ you could even save a parameter e.g. if your can be classified by , if it’s centered, you don’t need the anymore)
Batch norm transforms data back into normal distribution after each layer, so numbers don’t get to big / small over time (continously re-centering and re-scaling the data):
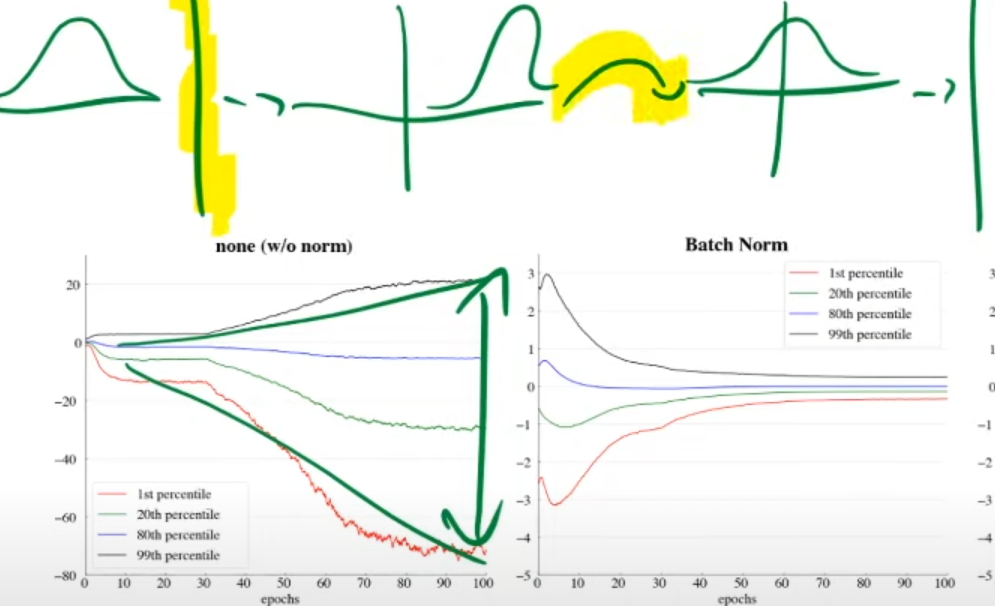
Drawback: You need to know all of the data points to determine the mean etc. You can still estimate / guess it with smaller mini-batches, but the smaller the batch, the worse the outcome.
Other benefits
Speeds up training
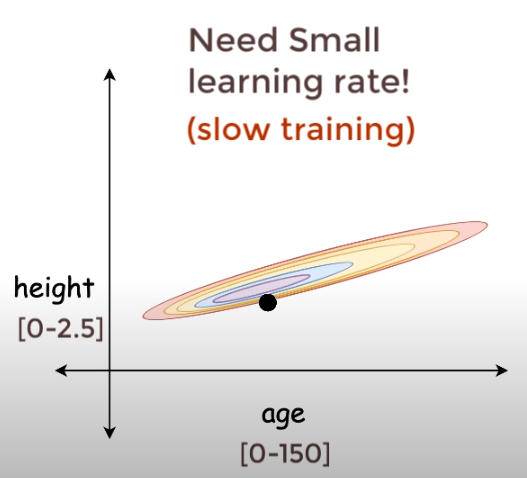
Small variations in height make a huge difference on the output, due to the varying scales-
After normalization → Loss smoothed
Circular transclusion detected: general/Normalization---Scaling---Standardization
The function is more symmetric
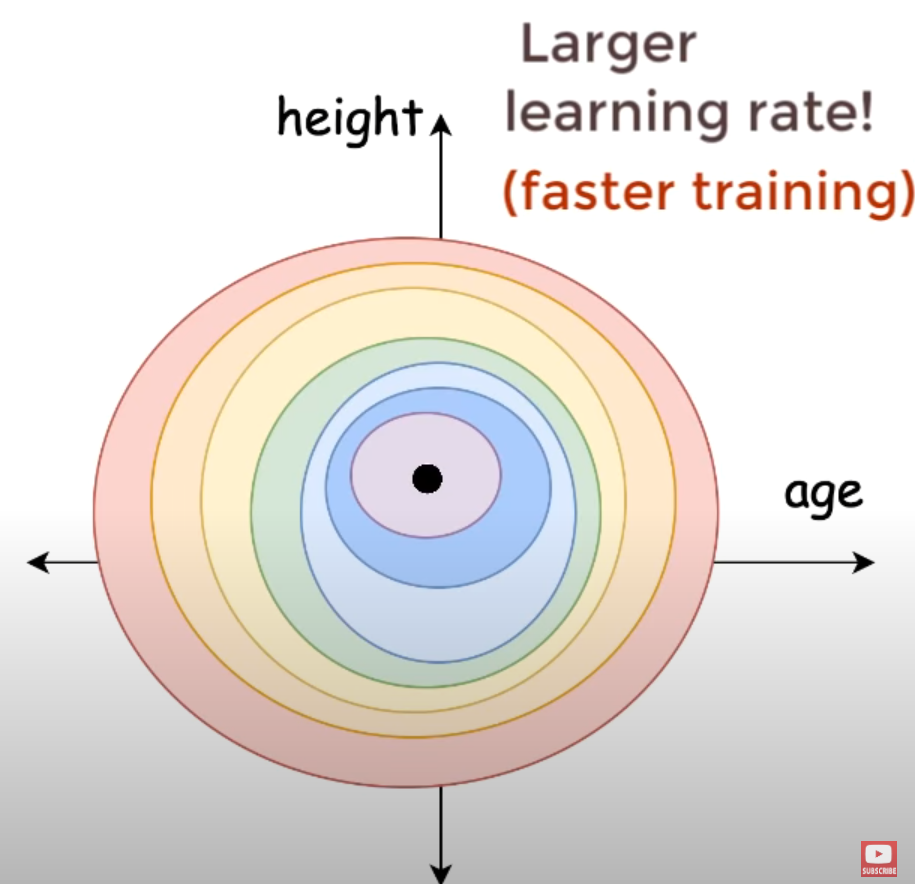
You could also use an adaptive optimizer like Adam, to have one learning rate for age and one for height (3d loss curve) but you should still normalize.
Makes initial weights less important
… we arrive at the minimum in a simmilar number of steps in the more symmetric circle but might take way longer depending on initial weights for the unnormalized data.
regularization
The random factor of the batch norm values plays a little into regularization (Introducing a little bit of entropy / jitter, due to the other examples; sorta a data augmentation).
Stability
Also aids model stability → Inputs are in simmilar ranges → More simmilar weights + Helps to prevent vanishing gradients / exploding gradients
In practice:
You could find better results depending on whether you put it before or after the activation function.
You can save parameters by turning of biases for all the other layers, since the offset is basically the bias.
torch.nn.Linear(..., ..., bias=False)Batch Normalization in depth explanation