→ standardization
Subtract the mean and divide by standard deviation.
→ (zero mean)
→ (unit variance)
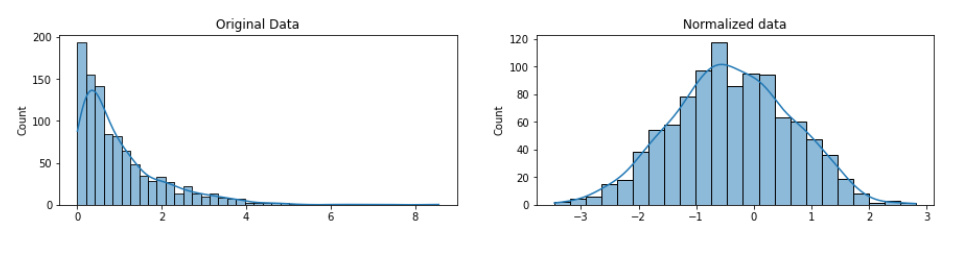
The standardization also normalzes the data, as it creates a standard normal distribution which scales the overwhelming majority of values to be in a small range and makes very small / large values very unlikely.
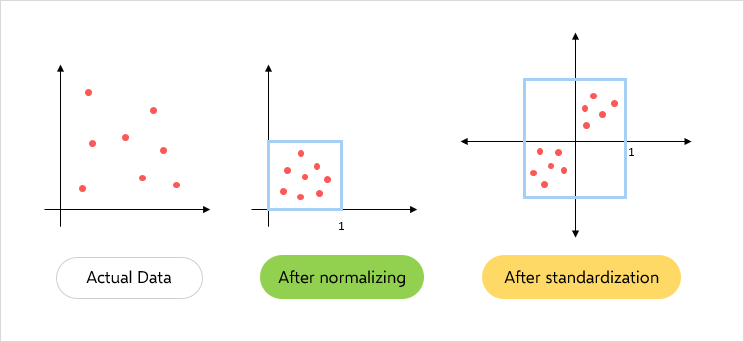
Normalizing is often used instead of standardizing in machine learning (standardizing has simmilar - even more useful - properties but does not strictly put the data in a range of [0-1] and only works best if your data follows a gaussian distribution).
What / When to normalize / standardize?
It’s usual to normalize a feature (column) so that, having done this for each feature, the features will be on more comparable scales.
Normalizing across rows usually doesn’t make any physical sense (Imagine mashing a person’s height, weight, and blood pressure together.).
Normalize training and test sets seperately or you will leak information into the test set!
If the features do not follow a normal distribution before standardization, they will not follow it after the standardization either. 1
e.g. an exponential distribution will stay exponential after standardization (even though the mean will be 0 and the std will be 1).
So normalizing might be better than standardizing if your data is not gaussian.
Normalization
In Algebra means dividing a vector by its length transforming the data into a range between 0 and 1.
Transclude of vector#^cf975b
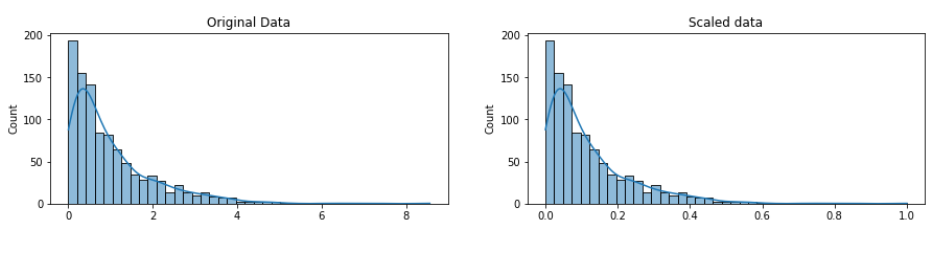
Min-max scaling also normalizes data between 0 and 1 or -1 and 1:
The normalization obtained by standardization does not strictly put the values in a range between 0 and 1 or -1 and 1 and it is also much more robust against outliers.
Types of normalization techniques in machine learning - comparison
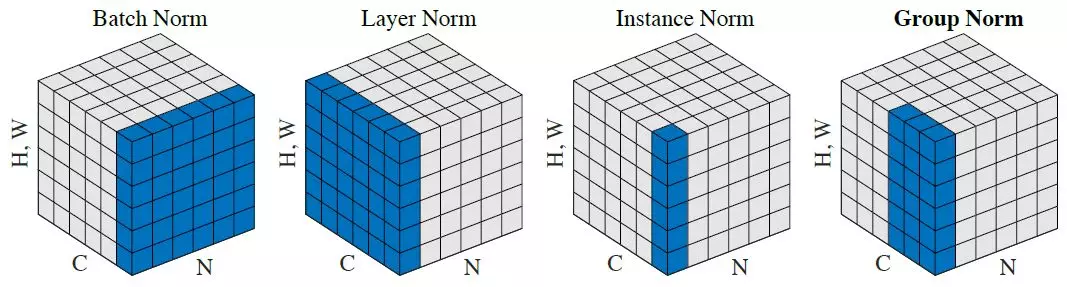
Normalizations compared visually (They all do the same thing but from different angles of the data)
channels, batch size, , 1D representation of outputs in channel
Explained by Yannik.
More rigorously: 3
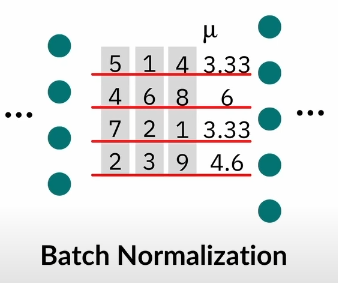
Batch Norm
Given an input batch , normalizes mean and standard deviation for each individual feature channel:
where are affine parameters learned from data; are the mean and standard deviation, computed across batch size and spatial dimensions independently for each feature channel:
uses mini-batch statistics during training and replace them with popular statistics during inference, introducing discrepancy between training and inference.
Instance Norm
In the original feed-forward stylization method, the style transfer network contains a layer after each convolutional layer. Surprisingly, Ulyanov et al. found that significant improvement could be achieved simply by replacing layers with layers:
Different from layers, here and are computed across spatial dimensions independently for each channel and each sample:
Another difference is that layers are applied at test time unchanged, whereas layers usually replace minibatch statistics with population statistics (=estimated mean and variance of the entire training dataset).
Adaptive Instance Normalization
Instance normalization normalizes the input to a single style specified by the affine parameters (). was introduced to adapt to arbitrarily given styles (in generative AI) by using adaptive affine transformations. receives a content input and a style input and aligns the channel-wise mean and variance of to match those of . There are no learnable affine parameters (like in or conditional ). Instead, it “adaptively computes affine parameters from the style input”:
TLDR.: Style is encoded through scaling and shifting of the values. ( and are learnt through a linear layer).
Like in the statistics are computed across spatial dimensions. Intuitively, let us consider a feature channel that detects brushstrokes of a certain style. A style image with this kind of strokes will produce a high average activation for this feature. The output produced by AdaIN will have the same high average activation for this feature, while preserving the spatial structure of the content image. In the original paper, and , are replaced by std and mean of the style input, normalizing it to the given style. A bit less flexible
Scaling
Batch Normalization vs Layer Normalization
Batch normalization is dependent on the batch size, as it normalizes on all the batches, whereas Layer Normalization normalizes per data point. (Batch Norm only good with bigger batch sizes >8)
Layer Normalization also performs the same operations during training and testing. (BN doesn’t)
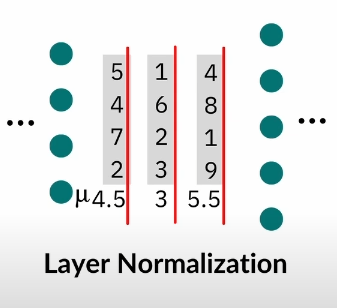
Layer Norm good for:
- sequences
- variable batch num workers
- parallelization
Not so good for:
- CNNs
- Features/Layers with different scales