
Streaming learning is an evolution of online learning that does not store past experience to train in mini-batches.
Link to originalWhy store past experience?
- It works stably for offline learnig
- Memory replay occurs in natural intelligence (albeit not with raw experience)
- Replaying samples multiple times extracts more information / is more sample efficient
- Stability
“Stream barrier”: Stability was a blocker for streaming RL in the pre-deep RL era (and the deep-RL era, until it got solved).
Why solve streaming deep RL?
- Fast adaptation to changes in the environment (which isn’t iid, usually)
- Unlocking new scaling regimes (test-time compute, time-based scaling, compute efficiency, …)
- real-time adaptive systems, local learning
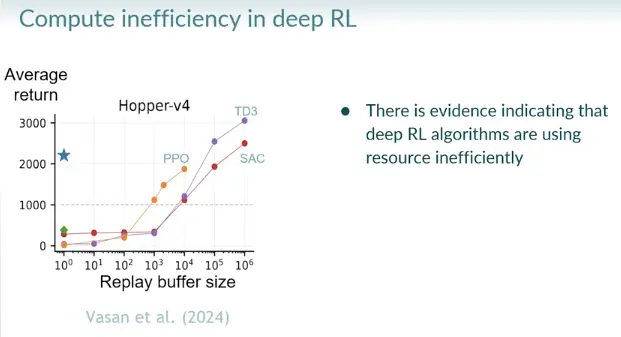
Traditional deep RL methods fail to overcome the stream barrier (below 1k avg return in hopper, nothing useful is learned).
Causes for the stream barrier
Learning with gradient descent can be unstable under nonstationarity (see catastrophic forgetting, loss of plasticity).
Mini-batch gradient descent somewhat this instability by i.i.d. sampling, but and since by definition we cannot do that, streaming learning faces the most extreme form of nonstationarity.
Pathologies under nonstationary deep learning
- Learning signals from different samples interefering with eachother
- Feature dormacy/saturation, vanishing gradients
- Large weights, exploding gradients
- Representation collapse, ill-conditioning, loss of curvature
Remedies:
Stream-X algorithms overcome the stream barrier, by applying techniques on top of classic RL algorithms with eligibility traces:
- sparse init
- layernorm
- obs and reward norm
- new optimizer for bounding step-size based on update size (most important)
The main idea is to prevent overshooting updates on a single example. See the note for context and details.
Link to originalAlgorithm 3: Overshooting-bounded Gradient Descent (ObGD)
This algorithm avoids the need for multiple forward passes by directly scaling the step size based on the theoretical bound of the effective step size. The scaling ensures updates remain controlled without requiring backtracking.
The key idea is to scale down the step size based on:
- How large the current error is, )
- How “steep” the current update direction is ()
- A safety factor that accounts for potential nonlinearity
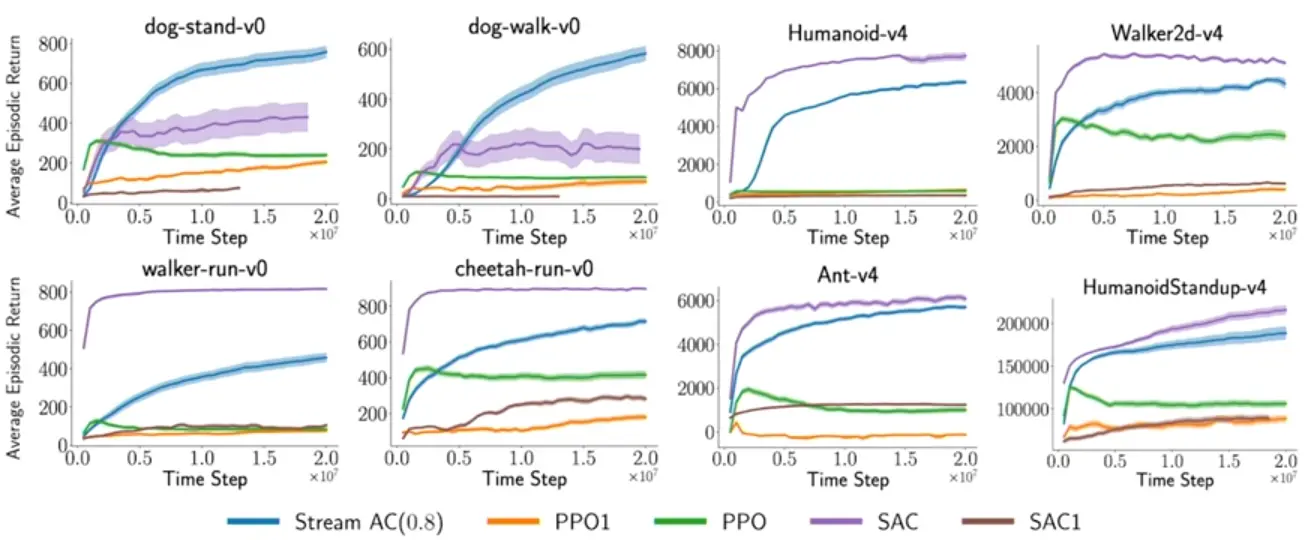
Stream AC uses only a single sample per step leading to the same performance but with orders of magnitude less compute:

I think this freed up compute is best spent on learning things in parallel ( meta learning). The continual learning properties are perfect for training OMNI-EPIC agents.
Carmack asks: “The CL tasks looks very daunting … if you make a billion sequential updates, you are almost guaranteed to guaranteed to destroy the earlier things … thoughts …?”
My two cents: Gradients update meta-learned weights, task-specific / contextual information of an agents lifetime are stored in the fast weights / context; the agent needs to learn to construct its own memory.
Like you need to discard or coarse grain information at some level. And it also won’t work to just store learning / adaptation mechanisms on just one level.
It all comes down to the multi-scale competency architecture again in the end.
And also a strong focus on what’s relevant for the current context / goal.
References
Rupam Mahmood , Streaming Deep RL, Upper Bound 2025
Streaming Deep Reinforcement Learning Finally Works