Goal: General purpose meta-learning, i.e. discovering learning algorithms that generalize very well.
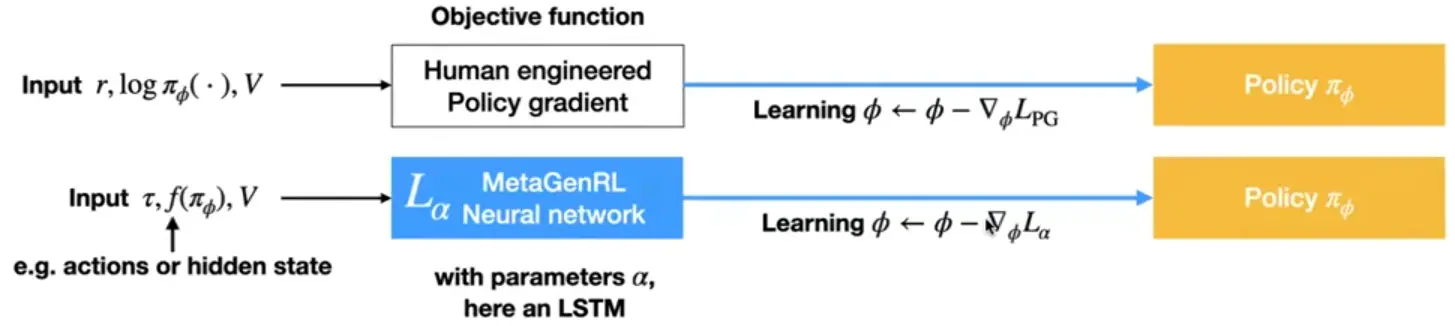
The objective for human-engineered learning algorithms (LAs) is fixed, given by the algorithm.
For meta learning algorithms, like MetaGenRL, it is parametrized by a neural network:
Meta-learning Spectrum: Less structure More structure
More structure: Learned Optimizers (Adam - adapts gradient landscape during learning)
Gradient-based optimization with learned initialization (MAML)
Gradient based with learned objective functions (MetaGenRL, LPG)
black-box optimization with parameter-sharing and symmetries (VSML, SymLA)
Least structure: Black-box (MetaRNN, RL², transformer, GPICL)
Meta-learning RNNs have been proposed to approach the problem of learning the learning rules for a neural network using the reward or error signal, enabling meta-learners to learn to solve problems presented outside of their original training domains. The goals are to enable agents to continually learn from their environments in a single lifetime episode, and to obtain much better data efficiency than conventional learning methods such as SGD. A meta-learned policy that can adapt the weights of a neural network to its inputs during inference time have been proposed in fast weights, associative weight networks, hypernetwork, and hebbian learning approaches. Recently works (VSML, Meta-Learning Bidirectional Update Rules) combine ideas of self-organization with meta-learning RNNs, and have demonstrated that modular meta-learning RNN systems not only can learn to perform SGD-like learning rules, but can also discover more general learning rules that transfer to classification tasks on unseen datasets.
Link to originalThe variable ratio problem:
Meta RNNs are simple, but they have much more meta variables than learned variables () leading them to be overparametrized, prone to overfit.
Learned learning rules / Fast Weight Networks have , but introduce a lot of complexity in the meta-learning network etc.
→A variable-sharing and sparsity principle can be used to unify these approaches into a simple framework: VSML.
… but transformers should improve this, as they have a much bigger effective state size / param ratio, as GPICL shows, right?
Link to originalGeneral purpose in context learners need diverse task distributions! (duh)
Circular transclusion detected: general/General-Purpose-In-Context-Learning-by-Meta-Learning-Transformers
Definition
Each task is defined by its dataset , . The optimal model parameters are:
Just like regular SL, but instead of sampling examples form one dataset, we sample datasets (representing different tasks) from a distribution of datasets.
→ The goal is to achieve good performance on out of distribution tasks.
→ Kinda everything is meta-learning in that sense, on a continuous spectrum, but the bar is continually moving higher.
Link to originalFew-Shot Classification
Link to originalTraining a classifier
We train a classifier with parameters on a dataset to output the probability of a datapoint belonging to the class given the feature vector , .
The optimal parameters maximize the probability of the true labels:When training with mini-batches :
In few-shot classification, we sample two disjoint sets from each epoch, where is a subset of labels (tasks) of : A support set and a training batch .
The support set is part of the model input. The goal is that the model learns to generalize to other datasets, by learning how to learn from the support set.How would such a network represent never-seen classes? It would need to output embeddings.
Viewing meta-learning as learner and meta-learner
The learner is trained to perform well on a given task.
The meta learner learns how to update the learner’s parameters via the support set :
For a classification task, and are optimized to maximize the objective:
Common approaches to meta-learning – how to learn
model-based meta-learning: –
metric-based meta-learning: – metric learning, is a similarity kernel
optimization-based meta-learning: – gradient descent updates of based on
(Some) Meta-learning approaches touch all fundamental aspect of machine learning at once
data : obtaining new tasks, …
model : data efficiency, …
loss : …
optimization : …
References
(2023) Louis Kirsch - Towards Automating ML Research with general-purpose meta-learners @ UCL DARK
(2021) Oriol Vinyals: Perspective and Frontiers of Meta-Learning
https://lilianweng.github.io/posts/2018-11-30-meta-learning/
