year: 2024/01
paper: https://openreview.net/forum?id=sKPzAXoylB
website: ICLR | Poster Link
code: https://github.com/mohmdelsayed/upgd
connections: continual learning, loss of plasticity, continual learning, optimizers, counterfactual regret, AMII, iclr 2024
Models optimized via Adam learn a task very proficiently, but if you introduce the model to new tasks - tasks on the exact same difficulty, the performance decreases over time.
What are these tasks of the same difficulty? E.g. MNIST classification, but you apply a random permutation to the pixels (the same random permutation to each image - that is the new task).
The model should ideally learn the new tasks just as well as the old one (and it is not even a requirement that it is able to remember the old task or anything), but with Adam, it doesn’t (loss of plasticity):
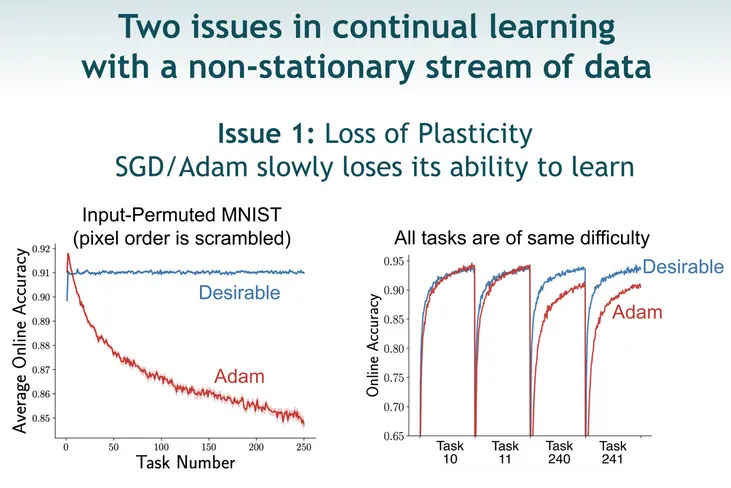
And we also care about the model being able to reuse feature extraction weights, instead of abruptly / drastically changing them (catastrophic forgetting):
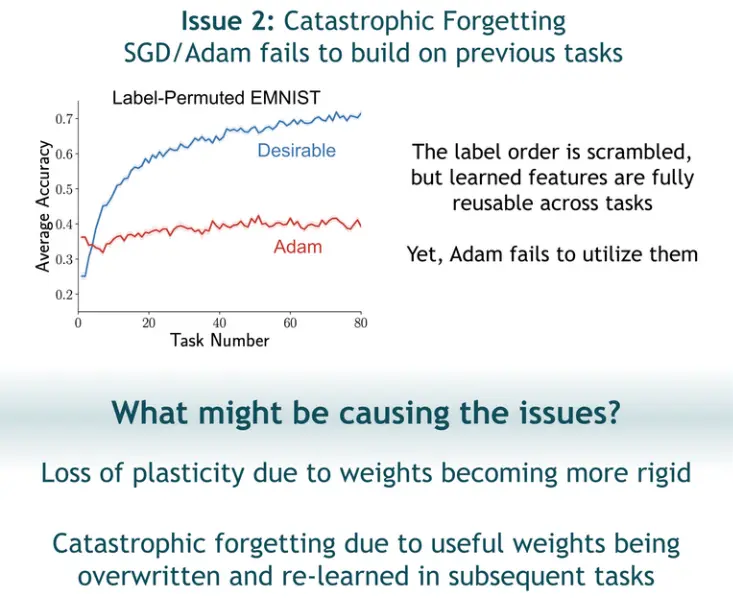
Question 1: Why does Adam lead to rigid parameters?
Because: Gradients get smaller or even die out, e.g. due to oversaturated or dead activations.
The network could also be trapped in some specific configuration space that’s hard to escape from.
Question
Why doesn’t just using LeakyReLU solve the issue? (at least the rigidity part, partially)

( X and Y?)
Question 2: Why do we need the perturbation paramter?
Because: As said above, the network can get stuck with dead activations / in some minima, where it does not get any or not sufficient gradient updates. In order to be able to jump out of there, receive signal, perturbations sampled from a cauchy distribution are added to the gradient updates of the less useful weights.
Observation: This computation of would be ridiculously expensive, since you need to do a separate forward pass for every single connection of the network, where the respective connection is deleted.
But somehow, it can be approximated with a taylor polynomial:

TODO
dig into the maths behind this (taylor expansion)

{kind=link}
And, we see it performs well:
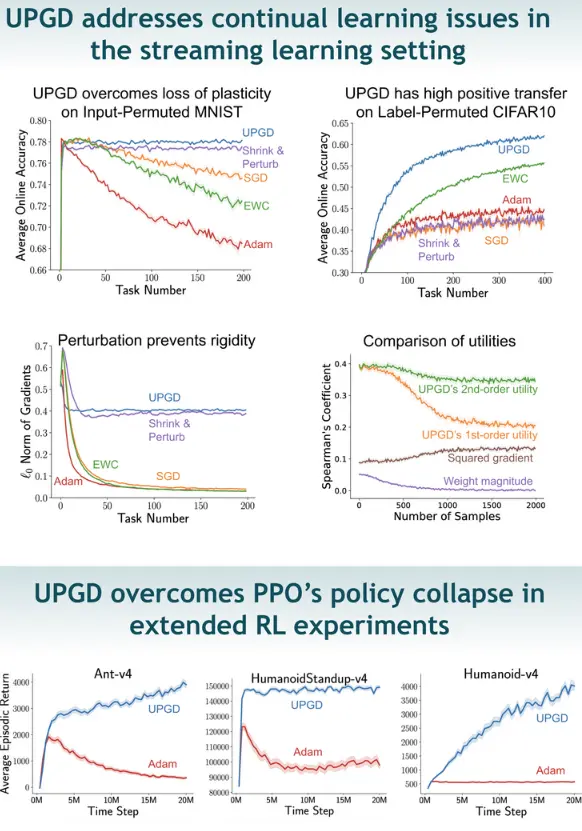
Gradient norm stays at a constant rate across tasks: After a few tasks, the useful shared parameters across tasks have been learnt and the model can efficiently swap change low utility connections → plasticity; while SGD and Adam lead to lower and lower gradients.
While PPO collapses after continuing training, UPGD improves or stays constant for millions of further training steps.
I don’t quite get the comparison of utilities chart yet. Esp. how squared gradient / weight magnitude would be used as utility.
But ig it shows that UPGD with 2nd order utility has the highest positive correlation out of the tested utilities.
Link to originalIs continual backprop ~= UPGD, just that they measure utility a little differently?
→ Indeed it is - UPGD is a better version - from the UPGD paper:
The generate-and-test method (Mahmood & Sutton 2013) is a method that finds better features using search, which, when combined with gradient descent (see Dohare et al. 2023a), is similar to a feature-wise variation of our method. However, this method only works with networks with single-hidden layers in single-output regression problems. It uses the weight magnitude to determine, such as classification (Elsayed 2022). On the contrary, our variation uses a better notion of utility that enables better search in the feature space and works with arbitrary network structures or objective functions so that it can be seen as a generalization of the generate-and-test method.
Link to originalTakeaways
→ Backprop is plastic, but only in the beginning (see Why does backprop loose plasticity?).
→ Small weights reduce loss of plasticity.
→ Continual injection of variability mitigates loss of plasticity.
→ Loss of plasticity is most relevant for systems that use small or no replay buffers, as large buffers can hide the effect of new data. Overcoming loss of plasticity is an important step towards deep reinforcement-learning systems that can learn from an online data stream.
→ deep learning is an effective and valuable technology in settings in which learning occurs in a special training phase and not thereafter. In settings in which learning must continue, however, we have shown that deep learning does not work. By deep learning, we mean the existing standard algorithms for learning in multilayer artificial neural networks and by not work, we mean that, over time, they fail to learn appreciably better than shallow networks.
→ Although Shrink and Perturb adds variability / injects noise to all weights, continual backpropagation does so selectively, and this enables it to better maintain plasticity - by effectively removing all dead units (→ higher effective rank; + less sensitive to hparams than S&P). Continual backpropagation involves a form of variation and selection in the space of neuron-like units, combined with continuing gradient descent. The variation and selection is reminiscent of trial-and-error processes in evolution and behaviour (as opposed to just following gradient ig).
→ Dropout, batch normalization/online normalization, and Adam also seems to reduce plasticity, though the paper did not investigate why. In general - these standard methods improve performance initially / on a static distribution, but are terrible for continual learning (or RL for that matter, as the policy is also ever changing - so much so, that periodically reinitializing network weights is better than keeping the trained one… provided there is a large buffer - else everrything would be forgotten).
→ Plasticity (adapting) != stability (memorizing; catastrophic forgetting). The utility in continual BP in its current form only tackles plasticity.