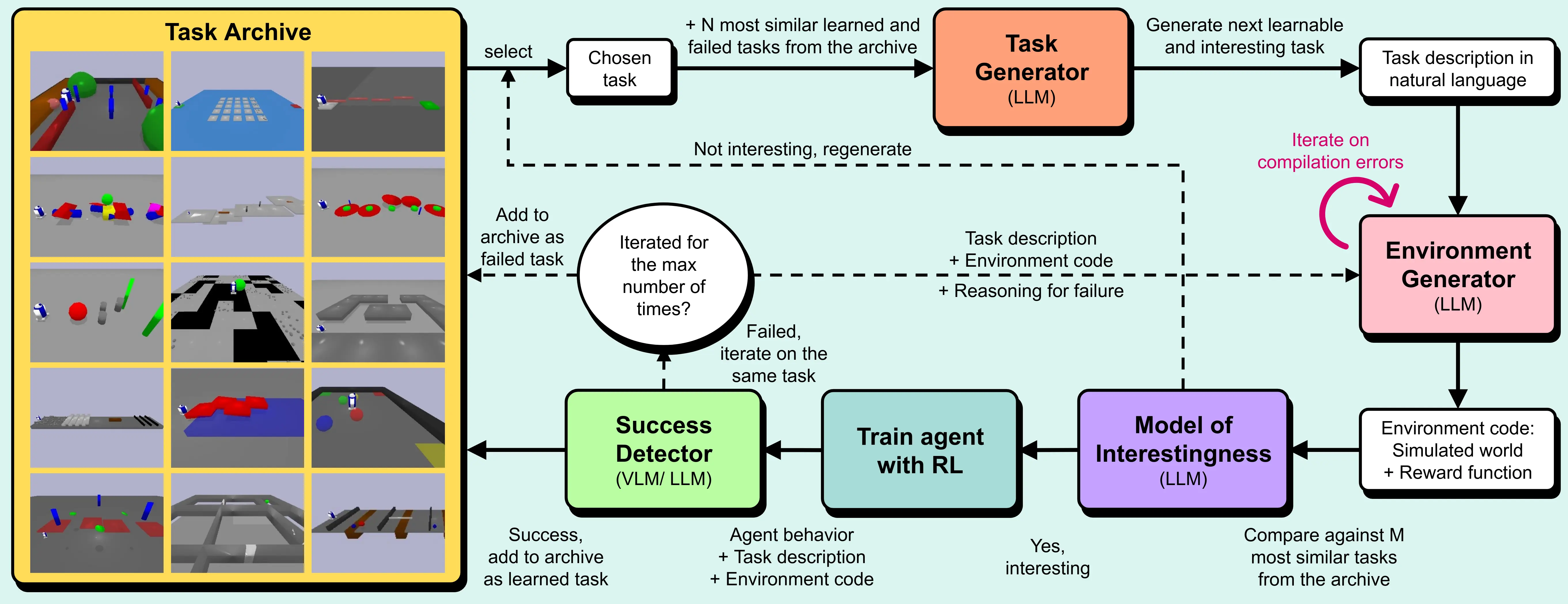
Omni epic is a framework for an open-ended environment/task generation system.
The goal is to generate tasks that are open-ended, interesting for humans, and learnable (not too easy/hard) for the agent given past successes/failures.
Task generator and model of interstingness (MoI) are both prompted with what makes an interesting / open-ended task.
The task generator creates a description of the next learnable and intersting task in natural language, which is passed to the environment generator LLM.
Its context are the N most similar learned and failed tasks to a task sampled from the archive (full code), plus base examples.
The weights of the distribution start out uniformly (all 1s), and is incremented by 1 for each unchosen task, reset to 0 for the chosen task and its N neighbours (ensuring task diversity1 ) 2.
The environment generator writes the code for the next task (given some scaffolding).
It also generates a dense reward function for training, and a success condition (in their case a function on the environment, often simpler, less hackable than the reward function).
If it fails after iterating on compilation errors for 5 times, the task is not recorded in the task archive, and a new base task is chosen.
Next, an LLM serves as Model of Interestingness for the task by comparing it to the M most similar tasks from the archive.
If the task is rejected, it is not recorded in the task archive, and a new base task is chosen.
A task-specific RL agent is trained to complete the task.
The agent is initialized from the weights of the agent for the most similar successfully completed task (at first from scratch).
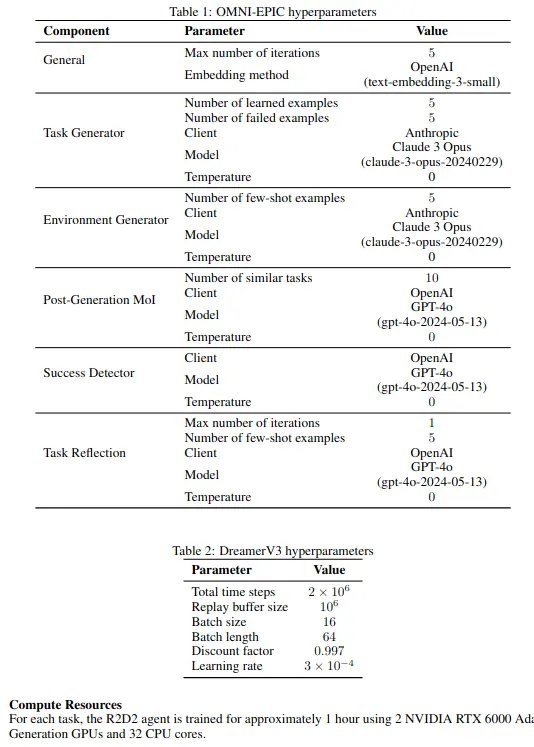
They (continue to) train a dreamerv3-based model for another fixed_number_of_steps.
Success is evaluated via the success-detection function, as VLM-based Sucess Detectors did not work well enough (yet) for their setup.
Failed tasks are added to the task archive, and iterated on in a reflect step (fresh LLM prompt) for the environment generator, including the reason of failure and code as additional context (to refine reward function, …), for a maximum number of iterations.
In theory, (V)LM based success detectors take task description, code + behavior (as screenshots, video, …) and output YES/NO.
My 2 cents: This is likely more successful for tasks in natural language / code, while allowing for a darwin complete version (as the paper itself acknowledges), see my comments below.
"It's like an intelligent mutation operator"
The N most similar tasks from the archive are like the parents.
"The Model of Interestingness is like a literature check"
You read some papers, are inspired ‘makes me think this would be a good idea’, but hopefully, if you’re doing your job right, instead of going and spending a year on that new idea, you first go do a literature check now that you have the idea at hand, to see if the idea has already been done before.
The next task should be interesting:
- Novel and creative compared to the tasks the robot has already learned.
- Useful according to humans, making it worth learning.
- Design rich environments with a large number of diverse objects and terrains...
- The task should be fun or engaging to watch
...
The new task can be considered interesting if one of the following is true, the new task is:
- Novel compared to the old tasks, to build a diverse skill set.
- Creative or surprising.
- Fun or engaging to watch.
- Not too easy for the robot to learn given its current skill set, progressing toward more complex challenges.
- Useful according to humans, making it worth learning.
...
You are an expert in Python programming and reinforcement learning. Your goal is to evaluate if a robot has solved a task. You will be provided with the task description, the corresponding environment code and an image containing snapshots of the robot attempting to complete the task. Your objective is to describe the image, reason about whether the task has been completed and determine if the robot has solved the task.
...
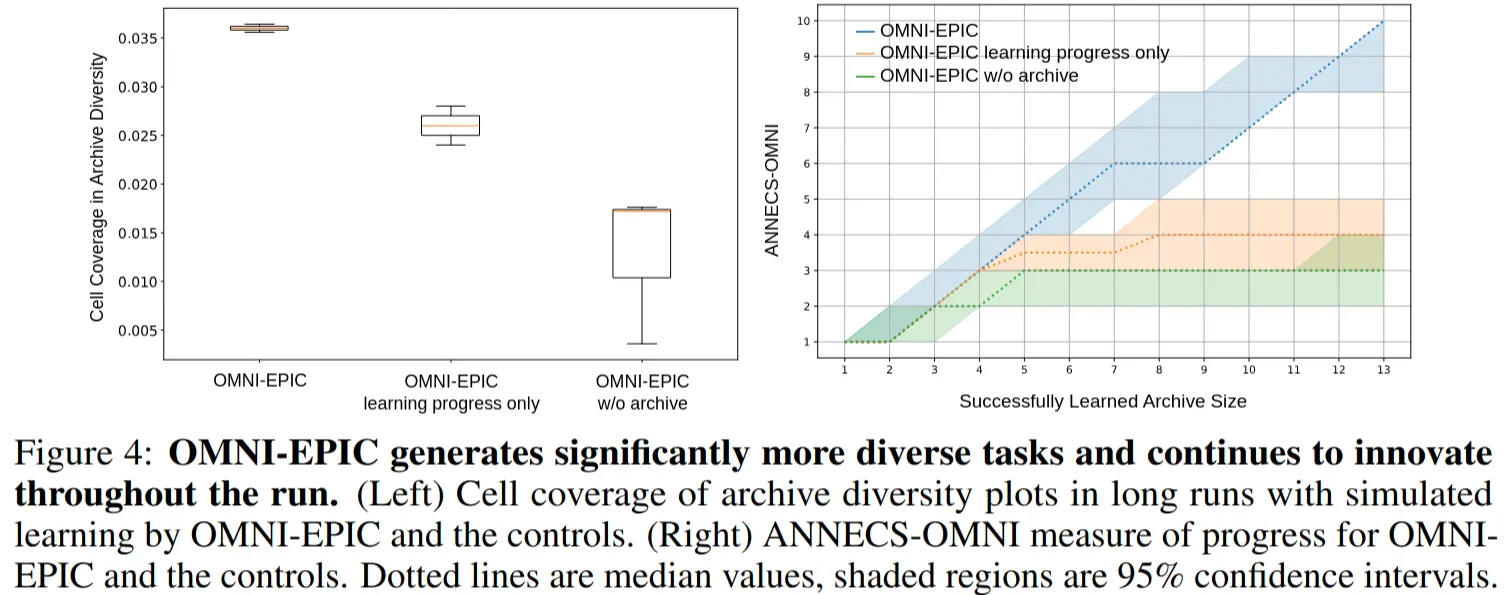
ANNECS-OMNI Metric (accumulated number of novel environments created and solved)
The original ANNECS tracks environments that are (1) learnable (not too hard/easy) and (2) eventually solved by the system.
the paper adds a (3)’rd criterion: the new task must be considered interesting compared to previous tasks.
the new task must be considered interesting compared to previous tasks (approximated here by asking an FM if the task is interesting given the archive of already-solved tasks)
They just employ the same prompt as they do for the MoI step.
How does OMNI-EPIC perform without being prompted for interestingness?
So the MoI clearly has an effect on task diversity that did not pleateau (tho compute was quite limited).
Connections
Open-endedness
OMNI-EPIC uses past experiences to generate novel and diverse challenges, continuously pushing the boundaries of what’s already learned.
Successful tasks serve as stepping stones for creating more complex yet learnable ones, while failed tasks provide insights into generating new tasks within the agent’s current capabilities.
… partial knowledge of stepping stones might be advantageous for creativity and diversity, much as human scientists and artists benefit from not being aware of everything that has come before.
“A potential limitation of our approach is the possibility of cyclic behavior where the task generator alternates between generating task types that are consistently rejected due to their similarity to existing tasks in the archive.”
While this scenario is unlikely in practice due to the stochastic nature of task generation and the diversity of the environment distribution, it cannot be completely ruled out. Furthermore, as context lengths increase with advancements in FM capabilities, the likelihood of such cyclic behavior would diminish even more.
The task code length varies around 200-400+ LOC, with a gym env like structure
Compare LLM summary with current knowledge/interaction-history/capabilities & goal-prompt.
Goal prompt can (needs to) also be meta, with an LLM automatically increasing difficulty. Memorization → Generalization, as per GPICL
EDIT: Simply plug this into an OMNI-EPIC-style system, allows to merge the objective setup above into natural language interestingness/success judges. Or rather: OMNI-X’s outer loop covers open-endedness and illumination, whereas during the rollout step, you use the similarity metric to train/evolve networks.
Weights are shared across all agents, but the state of the soup (context windows) is treated as task-specific.
The general self-organization, communication, problem-solving capabilities are meta-learned, while the problem-specific context/wiring/architecture stay preserved and separated, ready to bootstrap similar tasks.
Challenge: Context might get out of sync if shared weights constantly evolving. Potential mitigation: Discard context and initialize agents from scratch after N generations of no context re-use / continued training of the agent… 34
The “data-seeking outer-loop” of the open-ended exploration process is provided by OMNI-EPIC, generating an unbounded space of MDPs (“darwin complete”). At first, LLMs take on the task of active data collection themselves, but as the model gains in capability, it can task agents with collecting further data themselves, eventually replacing LLMs as the FMs driving OMNI-EPIC (which doesn’t run into bootstrap problems anymore, as the “rollout” agents and the agents with roles in OMNI-EPIC all have diffferent contexts and tasks, only sharing meta-weights. Just needs to be bootstrapped via LLMs teaching, until they’re sufficiently capable gathering in the real world).
Interestingness, grounding, learnability all directly translate of course.
They write, on AI-GAs:
However, such a system may constitute a large population of agents specialized to specific challenges. Moreover, exactly how such a co-evolving system might be implemented in practice remains an open question. We propose open-ended learning as a path toward not only an open-ended process, but one resulting in a single, generalist agent capable of dominating (or matching) any other agent in relative general intelligence over time. In this way, open-ended learning bridges the search for open-ended emergent complexity in ALife with the quest for general intelligence in AI.
This is covered by learning the algorithm that learns to solve tasks.
OMNI-EPIC should be simple to replicate if we generalize the approach to darwin completeness by operating purely in natural language / code space, without restricting to game-envs.
LLM can propose logic puzzles, arithmetic puzzles, tell the agent to fetch stuff from the internet, complete tasks on the internet, …
All that’s needed is a code env, and a base agent that’s capable of understanding natural language prompts. Tho even the later can be bootstrapped, consider this example. The “reward” would be natural language, test-time feedback, as we meta-learn the weights via ES over populations of tasks (or even populations per task, which is hopefully overkill…), the agent needs to meta-learn internal dense-rewards (and intermediate goals, …).
They mention VLMs are not accurate enough as success detectors for their tasks currently, but LLMs are surely accurate enough if tasks are in language / code space, instead of toy-game task space.
This allows an easier expansion of verifyable rewards from math/code to ineffable notions of human interestingness / open-ended tasks…
A curriculum for a pure natural language agent from scratchmight look something like the following:
L1: Elementary pattern recognition:
Copy patterns: A→A, B→B, test: C→? (learns: C)
Count length: AA→2, BBB→3, test: XXXX→? (learns: 4)
Next in sequence: 1→2, 5→6, test: 9→? (learns: 10)
Simple math: 1+1→2, 2+2→4, test: 3+3→? (learns: 6)
…
L2: Basic language features:
Categories: cat→animal, rose→plant, test: dog→? (learns: animal)
Properties: ice→cold, fire→hot, test: snow→? (learns: cold)
Functions: eat→food, drink→water, test: breathe→? (learns: air)
Opposites: big→small, hot→cold, test: up→? (learns: down)
Plurals: cat→cats, dog→dogs, test: bird→? (learns: birds)
Completions: "Grass is..."→"green" or “a plant”, test: "Snow is..."→? (learns: "white" or “cold”)
Questions: "What color is the sky?"→"blue", "What shape is a ball?"→"round", test: "What color is grass?"→? (learns: "green")
…
L3: Learning functions / increasingly complex pattern recognition:
Transformations: "reverse ABC"→"CBA", "uppercase cat"→"CAT", test: "reverse 123"→? (learns: "321")
Multi-step: "count letters in cat"→"3", "add two and three"→"10“, "reverse ABC then count letters"→"3"
...
Is it a good idea to have static training configuration for the task-specific agents? Or rather: is it tractable / desireable to not have early stopping / success detection?
If an agent solves a task reliably mid-training, I think we could just mark it as successful?
Like I suppose we should define the success criterion in a way to allow applying it onto training checkpoints, considering success rate/margin (on a test-set, if available. For some, esp. higher-level tasks or things like game levels, it might just be solved or not solved, I guess.)
Stream of consciousness on how to implement OMNI-EPIC in a darwin complete way:
literally just omni epic structure
but replace env specific stuff
only scaffolding is access to a shell, with optional internet access. initially neither is required for the agents, tho it’s useful for the FMs in OMNI-EPIC.
adapt prompts
tasks/task datasets can be generated by the LLMs “by hand”, by fetching from the internet, by writing code that generates a task set
for the dead-simple approach… leave everything else as is? (well except exchanging dreamer with Smol LM + GRPO, since we want to train on natural language, and are on a budget; but there’s so much (basically) free usage of many (basically) frontier models, it can be run over weeks and months as a background job; e.g. envoking claude via shell every few hours to make optimal use of max plan sessions … not against TOS if not directly training on its output)
Instead of grpo, we should try adapting the latest streaming RL algos to LM as it seems a perfect fit.
Maybe sth like EvoTune could be added on top, to optimize the task generators etc. too, until they can be replaced by superior soup instances.
That’s what they do in the code. In the paper theyjust mention uniform sampling. ↩
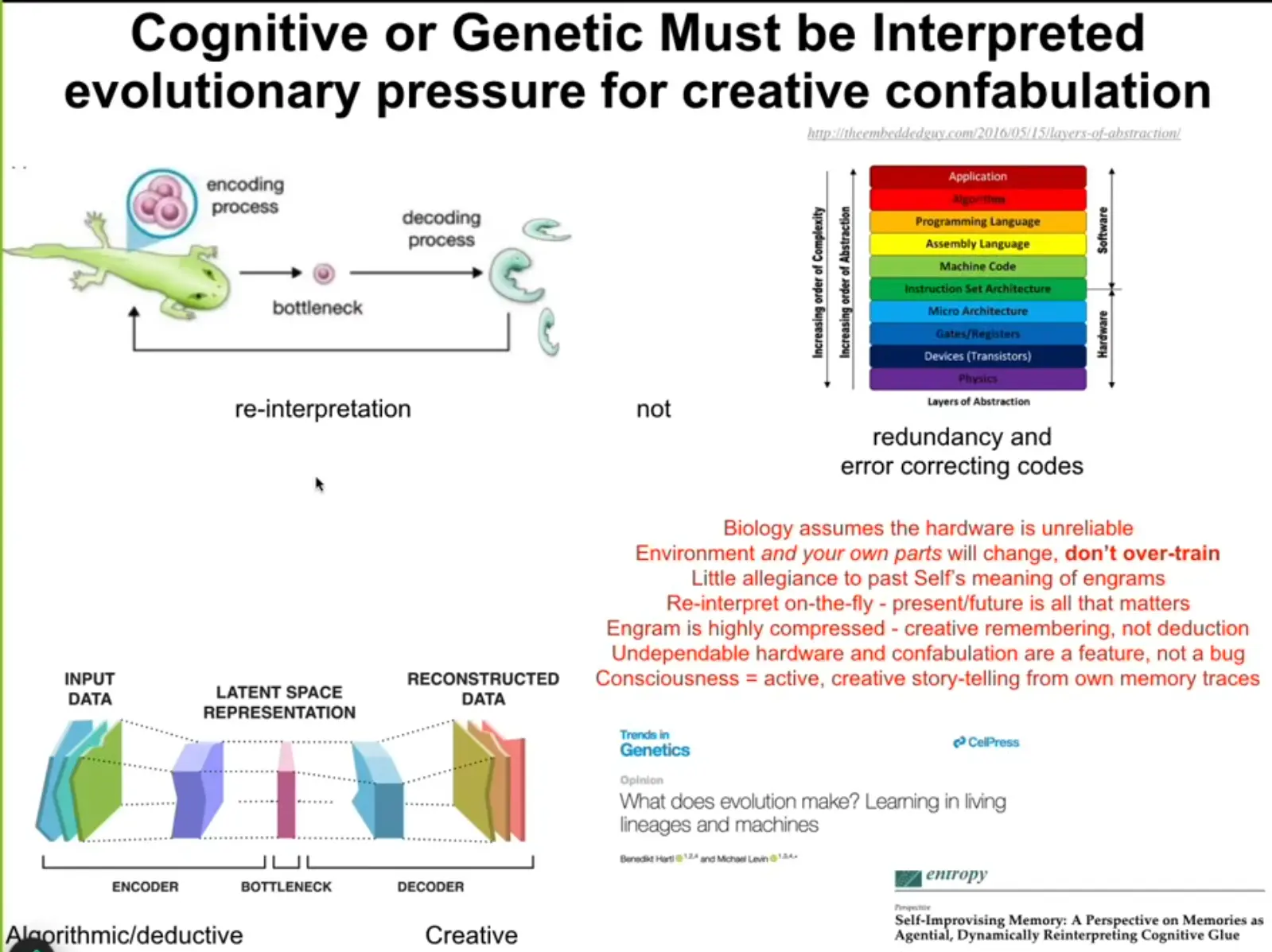
… might this be an analog to the utility of death in natural evolution (EDIT see also Evolution as Backstop for Reinforcement Learning): Communication protocols grow outdated as hardware continues to evolve. Agents with a fresh context are bootstrapped via imiation learning from parent agent’s successful tasks. This would really create cycle where we re-initialize, but can bootstrap in an optimized form, building on top of 1) already learned behaviors 2) already discovered interesting tasks, just like a human growing up in the 21st century doesn’t need to rediscover the newtonian mechanis. Of course it would be much preferred if the protocol was stable enough to just smooth out the weight changes over time (which should be the case to a degree as it’s forced to be adaptible, which would be reinforced by training on outdated com protocols), but maybe that actually goes against the philosophy. Unburdened by what has been. Because in order for the smoothing to work, we can’t have infinite breadth of agents that OMNI-EPIC has… retraining each task on new weights continuously is obviously not feasible. Death might be a feature after all. Just imagine your biological hardware getting updated abruptly, without acclimating your existing pathways. You couldn’t re-interpret your memories. Just doesn’t work. There’s no way to make this work without limiting the breadth of the space the agents explore, or overwhelming resources (keeping agents weights historized…). Hm, but isn’t OMNI-EPIC doing the latter? So by not doing that, we’re restricting diversity in weight space. But this might be a tradeoff. Learning a general foundational self-organizing architecture that can adapt to new tasks is what we are after, not the best architecture for each task. Agents should specialize in-context / during their lifetime. I’m reminded of the picture that michael levin likes to paint, of the genome vs. intelligence ratchet, and the genomic bottleneck (genome[bottleneck] -> decoding[creative reinterpretation] -> phenotype[selection] -> genome[mutation] -> ...). Running through the bottleneck of occasionally loosing the exact context of this or that agent … maybe due to a combination of natural senescence and rare agent invocation. It does add the complexity of adding a bootstrap phase for the uninitialized agent, but it seems natural. Biological organisms don’t live forever. Or maybe they could (there’s no fundamental limitation and there’s only a soft storage space issue for natural evolution ability “store the full tree of evolved creature’s weights” (letting them co-exist/co-live)…), but it might not actually be gloabally optimal for open-endedness and adaptability. Discarding old agents can help overcome local optima. Actually, different weights → different species, right? So that’s it. We’re restricting diversity in that regard, by not letting the weight space branch (because senescense for fostering diversity in agent space can coexist with branching weights). ↩
If we accept death for a moment… it makes things a lot simpler, operationally. But also conceptually. The genome is then always a developmental encoding. The phenotype is the specific arrangement and context of the cells. A “task” is a lifetime. Gets naturally more complex and longer with capability. Now you could share the weights across the entire archive and treat a batch of tasks as the population (in addition to a population of agents for each task), which is clearly against the entire point. Or, you allow for diversity/niches/… and branch the weights for each task. It’s not even more expensive other than for storing the weights. And the “beneficial effect” of averaging ↩
{kind=link}
{kind=link}