year: 2025/05
paper: questioning-representational-optimism-in-deep-learning-the-fractured-entangled-representation-hypothesis
website: https://x.com/kenneth0stanley/status/1924650124829196370
code: https://github.com/akarshkumar0101/fer
connections: representation, Kenneth O. Stanley Akarsh Kumar, Jeff Clune, Joel Lehman
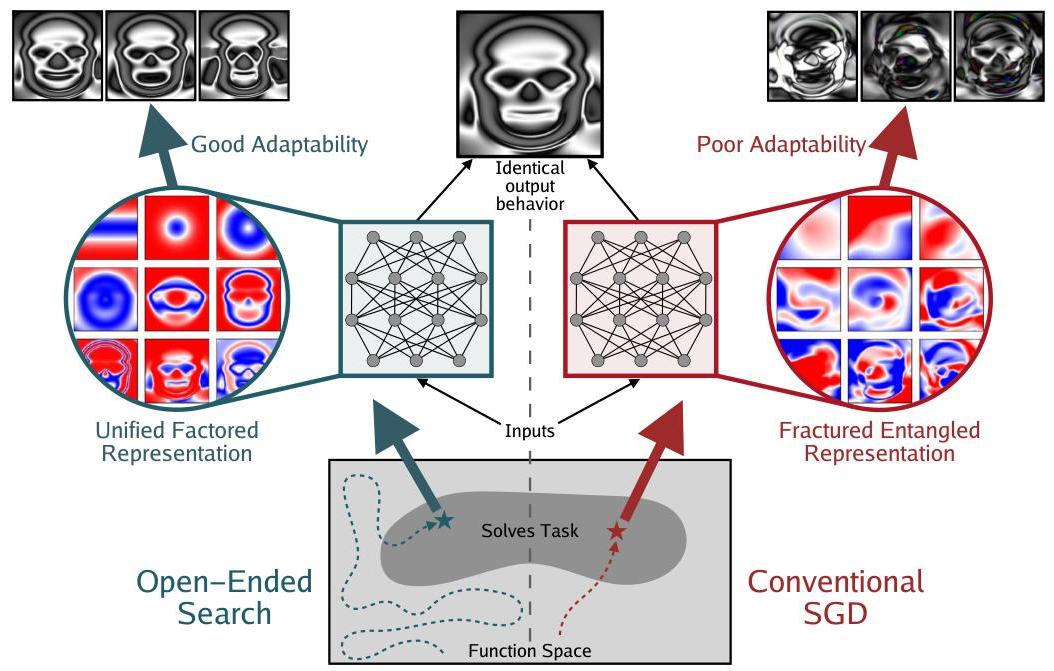
In a nutshell
- The representations of images generated by CPPNs evolved via NEAT selected by humans in Picbreeder are compared to the same images reproduced via conventional SGD on computationally indentical dense MLPs
- Each CPPN/MLP generates a single image as its entire output space.
- Both have the exact same network structure.
- Comparing the two networks & training approaches, two different categories of representation emerge
- Fractured Entangled Representations (FER): Information underlying the same unitary concepts is split into disconnected pieces. Importantly, these pieces then become redundant as a result of their fracture: In other words, where there would ideally be the reuse of one deep understanding of a concept, instead there are different mechanisms for achieving the same function.
- Unified Factored Representations (UFR): Ideally, FER would be absent after training and internal representations would be the opposite: unified (a single unbroken function for each key capability) and factored (keeping independent capabilities separated so that they do not interfere with each other). In practice, a well-factored representation should resemble a modular decomposition of the desired behavior.
- While the image produced by conventional SGD produces an ~identical looking skull, its underlying representation is completely different.
- The imposter skull is a simple metaphor for a vastly more complex “imposter intelligence.” It shows the danger of judging a book by its cover, except here, the “cover” is the sum total of all its behaviors.
- The image can be seen as a “micro-metaphor” for the entire knowledge of an LLM
- Mistakes made by state of the art LLMs/image generation models point towards FER being present even in larger models, just masked behind a bigger capability surface.
- E.g.: Being able to count items of one type but failling for an identical prompt with just the type swapped; being able to generate a human hand with two thumbs but not an ape hand, … (gpt3 on text (whereas gpt4 gets it), 4o on image gen)
- → FER seems to persist even as models reach massive scale, or just shifts it closer towards the frontier of knowledge, where the least data is available.
- So current models seem limited to solving problems in the realm of the well-known, progress being made by covering blindsposts individually, whereas addressing FER could drastically increase their skill-acquisition efficiency, esp. at the frontier of knowledge.
- This matters, not just for efficiency/redundancy, but also for creativity, adaptability, generalization and learning: Representation is not about capturing a particular pattern or output behavior. Rather, it is about whether the system can build on the regularities of that representation to learn and generate new behaviors.
- Open question: To what extent does FER cause issues around sample efficiency, reliability, hallucination, OOD generalization, failures on simple tasks, continual learning, etc.?
- How to improve representations / What causes UFR / FER? Hints:
- Picbreeder networks first develop symmetries (with the help of humans choosing interesting patterns), then complex features on top.
- The SGD Skull took a direct path to the skull without building regularities along the way.
- Untangling fracture is harder than having it in the first place.
- → The order in which a concept is learned is fundamental to the representation eventually achieved.
- → Reasoning (about what to learn next) is missing at train-time; Knowing what to ignore
- → Efficient re-analysis and re-compression of information
- NEAT might help develop UFR as it’s developing simple → complex nets
- But NEAT tasked with reproducing pictures like SGD in this papers leads to more bloated nets / FER too, see this.
- → The open-ended (non-objective) search process in Picbreeder is potentially a more fundamental factor
- UFR is not just compression, which on its own might miss features like the ones represented by the jaw opening or winking neurons for the skull.
- factorization captures this aspect of good representation; factorized representations enable compositional generalization
- Main new insight(s) from this paper:
- Neural networks can exhibit UFR, albeit from a radically different training procedure than current practice.
- There is a path to such factorization without the need for extensive representative examples.
Conventional SGD | Is SGD the culprit?
While SGD-driven optimization in the experiments in this paper does yield FER, it is possible that novel variants or uses of SGD, such as in the service of novelty instead of a conventional specific objective, could exhibit much less of it. Therefore, we choose the term conventional SGD to refer the application of SGD on a fixed architecture with a single target objective in the experiments in this paper. It is also important to bear in mind that FER is likely to emerge in other settings as well (e.g. in second order methods and evolutionary algorithms), especially or most likely when optimizing to solve a single fixed objective, so the issue is almost certainly not exclusive to SGD.
Represenation matters for creativity, adaptability and learning
If the model does not fundamentally represent that the skull is symmetric (even though it can draw a single nice looking skull) the opposite will happen: almost any random perturbation would break the symmetry or disorganize the image in a chaotic and entangled manner (as occurs with the skull produced by conventional SGD, Figure 6b). In effect, this kind of representational pathology is a failure of representing symmetry and other regularities that will cripple imagination, creativity, and learning: if you do not understand that faces are symmetric, even if you memorize a single face and draw it to perfection, you will have little ability to conceive of any other face or take meaningful creative leaps. An understanding of the underlying symmetry is crucial. Based on these arguments, at least in the case of the skull, it may matter how the skull is represented even if the output image is perfect at every pixel location.
…
This problem is deeper than just inefficiency: it limits the ability of the model to build anything new (like a new skull or new face) that would require an understanding of faces. Even though it draws a perfect skull, it does not understand the underlying regularities or any modular decomposition of what it is drawing at all.
…
In effect the learned skull is an imposter — its external appearance implies its underlying representation should be authentic, but it is not the real thing underneath the hood
Connections
Link to originalGATO showing negative transfer learning – learning a new game is harder if done after learning other games in parallel.
It is a challenge to just not get worse!
This “loss of plasticity” in a network with continuous use is a well known phenomenon in deep learning, and it may even have biological parallels with aging brains at some levels – old dogs and new tricks. But humans
It may be necessary to give up some initial learning speed “learn slow so you can learn fast”
→ Connection to Questioning Representational Optimism in Deep Learning - The Fractured Entangled Representation Hypothesis? Sacrifice initial learning speed / task specific perf in favour of building solid representations / building blocks that allow you to perf well / recombine / adapt to other tasks down the road. Maximize adaptability?
Order matters… first simple patterns then complex ones… reminds me of:
Link to originalIt’s easier to first memorize and then generalize, rather than trying to generalize right away!
The more you bias your batch, the faster you can learn! There is a sweetspot, where you completely avoid the loss plateau phase, by allowing the model to memorize more quickly and then generalize.
This means curriculum learning works here!
But ofc curriculums aren’t everything, you also need the ability to reorganize information as often times you can simplify concepts after learning more about them / making connections to different fields, as the paper also explains.
I think you shouldn’t try doing everything in weight space tho!
You need to meta-learn the ability to do this in-context, as this is highly experience dependent.
And soup’s architecture is aiming to optimize exactly that.
Also, I think the point about “many decisions on order are arbitrary” “ordering is hard” are really weak.
Like doesn’t OMNI-EPIC show we can automate ordering with notions of human interestingness?
Doesn’t arbitraryness amount to serendipity and diversity? A “perfect curriculum” doesn’t exist by definition and is obviously impossible to find for any goal for many reasons but it’s also … not needed at all?
For example, both processes are likely happening simultaneously. Consolidation can happen even as new kinds of data become admissible. Furthermore, it is conceivable that humans also transiently hold more than one representation simultaneously, perhaps experimenting with different conceptualizations of an idea until one ends up winning. While that scenario sounds reminiscent of FER, an important distinction is that this hypothetical human diversity of representations is intentional, benefits from self-awareness, and temporary. That is, the process of trying multiple frameworks and pruning as more is learned is arguably more organized than in an LLM, though much is still unknown.
Yes, yes, yes, exactly. The cortical columns voting.
Model cortical columns by tiny transformers.
Each transformer has its own world model, it’s own little context / task.
They can hold multiple world views simoultaneously.
Agreement can be reached via discourse.
Representation and consolidation happen in context at inference time.
Extra details
CPPN images are analogous to an entire space of inputs and outputs
We often think of individual images generated by large models as a single instance of generation. For that reason, it is important to recall that, though they appear superficially similar, the CPPN images in this paper are not analogous to a single large model generation step. Instead, these CPPN images are analogous to an entire space of inputs and outputs: each pixel coordinate is an input and the corresponding pixel is the output. In this way, CPPN images are actually a metaphor for the entire behavior and intelligence of a neural network (analogous to a comprehensive intelligence and personality profile/snapshot of a neural network, such as an LLM).
"both have the exact same network structure"
Code up the layerization to convince myself
Additional Ideas / Thoughts / Comments
→ FER seems to persist even as models reach massive scale / does not magically scale away.
FER likely plays its part in the slowing progress at the frontier of the current training paradigms:
Spaghetti Neurons, Synaptic Plasticity, and Mortality
The order in which a concept is learned is fundamental to the representation eventually achieved
I wonder how much this affects humans. I bet a lot. I grew up with astrophysics and all kinds of science documentaries. That surely had an outsized impact on my curiosity and interests.
To which extent can such representational deficiencies be refactored in humans as they grow older? I guess it’s closely linked to synaptic plasticity which I know way too little about to now make connections and I herby channel all my power to stop myself from going down another goddamn rabbit hole rn.
Refactor is prlly a good term tho. I bet there’s many analogies you can draw to growing codebases…. and links back to that thought I had about death @ OMNI-EPIC footnote … rewrites are oftentimes more efficient than trying to patchwork an existing system. So at least in nature death makes a lot of sense. But with sufficiently advanced technology to refactor and/or no external pressure to get rid of the sluggish system… immortality is feasible.
So interesting.
But the death I alluded to in that footnote was more about the baggage in-context / the wiring/set up of the self-organized system. Which well yh if you think about it genome vs instance is exactly that. The genome of a species doesn’t die with a single specimen.
Somewhere here is also a profound connection to planaria and the evolution/intelligence ratchet but I’m tired and need to first actually read levin’s papers.
Also, and I mean this was obvious before this paper too, but this also suggests education should be radically transformed (mentoriship; hands-on; from first principles >>>, teaching to think instead of teaching to be a tool… similarily ALIFE vs LLMs)