Monte Carlo Gradient Estimation in Machine Learning
year: 2020
paper: https://arxiv.org/pdf/1906.10652
website:
code:
connections: monte carlo method, machine learning
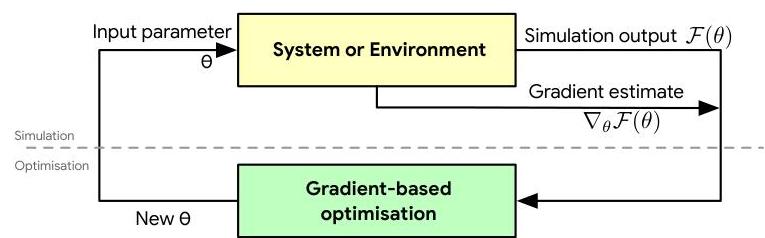
Whereas in a typical optimisation we would make a call to the system for a function value, which is deterministic, in stochastic optimization we make a call for an estimate of the function value; instead of calling for the gradient, we ask for an estimate of the gradient; instead of calling for the Hessian, we will ask for an estimate of the Hessian; all these estimates are random variables.
Problem statement
is a probabilistic objective of the form:
where is a function of an input variable with “structural parameters” , evaluated on average with respect to the input distribution with distributional parameters .
is referred to as cost and as measure 1. They call this a “mean-value analysis”.→ This is a general framework that allows us to cover problems from queueing theory and variational inference to portfolio design and reinforcement learning.
We want to learn by optimizing , so we care about its gradient:
They call this the “sensitivity analysis” of , i.e. the gradient of the expectation with respect to the distribution parameters . It characterizes the behavior of the costs’s sensitivity to changes in the distribution parameters. 23
→ This gradient lies at the core of tools for model explanation [probabilistic systems] and optimisation.
But this gradient problem is difficult in general: we will often not be able to evaluate the expectation in closed form; the integrals over are typically high-dimensional making quadrature ineffective; it is common to request gradients with respect to high-dimensional parameters , easily in the order of tens-of-thousands of dimensions; and in the most general cases, the cost function may itself not be differentiable, or be a black-box function whose output is all we are able to observe. In addition, for applications in machine learning, we will need efficient, accurate and parallelisable solutions that minimise the number of evaluations of the cost. These are all challenges we can overcome by developing Monte Carlo estimators of these integrals and gradients,is not considered in the following ( shapes how each sampled is scored, but don’t affect how it is sampled, in this setup) which is why the paper drops it, even though may depend on it.
Monte Carlo estimator of the expectation
The monte carlo method lets us approximate the estimation in cases where we can’t (easily) evaluate the integral in closed form, by drawing iid samples from the distribution , and taking the average of the function evaluated at those samples:
I.e. we approximate the expectation by the empircal/sample mean of samples.
All we need is an integral of the form shown above, and a distribution that we can easily sample from.The resulting quantity is a random variable, because it deends on the set of random variates used.
Desirable properties of Monte Carlo estimators:
Consistency
The estimator should converge to the true value as the number of samples increases:
\bar{\mathcal{F}}_{N} \xrightarrow{a.s.} \mathcal{F}(\theta) \text{ as } N \to \infty
Following the strong law of large numbers.
Un biasedness The estimate of the gradient should be correct on average. Unbiasedness is always preferred because it allows us to guarantee the convergence of a stochastic optimization procedure.
\mathbb{E}{p{\theta}(x)}[\bar{\mathcal{F}}_{N}] = \mathcal{F}(\theta)
This follows from the linearity of expectation and the fact that the samples are drawn from :
\begin{align*}
\mathbb{E}{p{\theta}(x)}[\bar{\mathcal{F}}{N}] &= \mathbb{E}{p_{\theta}(x)}\left[\frac{1}{N} \sum_{n=1}^{N}f(\hat{x}^{(n)})\right] \
&= \frac{1}{N} \sum_{n=1}^{N} \mathbb{E}{p{\theta}(x)}[f(\hat{x}^{(n)})] \
&= \frac{1}{N} \sum_{n=1}^{N} \mathcal{F}(\theta) \
&= \mathcal{F}(\theta)
\end{align*}Minimum variance. Evolution Strategies as a Scalable Alternative to Reinforcement Learning also makes good points about variance reduction.
Comparing two unbiased estimators, the one with lower variance is better.
Low-variance gradients allow larger learning rates (→ fewer steps) and more stable convergence.
Computational efficiency
Less evaluations/samples (linear cost in the number of parameters) + parallelizable = good.
Making a clear separation between the simulation and optimisation phases allows us to focus our attention on developing the best estimators of gradients we can, knowing that when used with gradient-based optimisation methods available to us, we can guarantee convergence so long as the estimate is unbiased, i.e. the estimate of the gradient is correct on average.
Sources of stochasticity:
- environment
- (optionally) SGD (sampling minibatches)
The Bias-Variance Tradeoff Different gradient estimators (score function, pathwise, etc.) have different bias-variance properties.
Score function is unbiased but high variance. Pathwise (reparameterization) has lower variance but requires differentiable f(x).Example applications:
Variational Inference
Link to originalVariational inference
Variational inference is a general method for approximating complex and unknown distributions by the closest distribution within a tractable family. Wherever the need to approximate distributions appears in machine learning—in supervised, unsupervised, reinforcement learning—a form of variational inference can be used.
Consider a generic probabilistic model that defines a generative process in which observed data is generated from a set of unobserved variables using a a data distribution and a prior distribution .
In supervised learning, the unobserved variables might correspond to the weights of a regression problem, and in unsupervised learning to latent variables.
The posterior distribution of this generative process is unknown, and is approximated by a variational distribution , which is a parameterised family of distributions with variational parameters , e.g., the mean and variance of a gaussian distribution. Finding the distribution that is closest to (e.g. in the KL sense) leads to an objective, the variational free energy, that optimizes an expected log-likelihood subject to a regularization constraint that encourages closeness between the variational distribution and the prior distribution .Optimising the distribution requires the gradient of the free energy with respect to the variational parameters :
This is an objective in the form we have in monte carlo estimation, where the cost function is the term in square brackets, and the measure is the variational distribution .
This problem also appears in other research areas, especially in statistical physics, information theory and utility theory. Many of the solutions that have been developed for scene understanding, representation learning, photo-realistic image generation, or the simulation of molecular structures also rely on variational inference.
Reinforcement Learning
Link to originalPolicy gradient methods
Let be sampled from initial distribution . A trajectory is generated by:
- Sampling actions:
- Sampling states:
until reaching a terminal state. At each timestep, a reward is received. The goal is to maximize the expected total reward (assumed to be finite).
Policy gradient methods maximize the expected total reward by estimating the gradient :
where can take various forms, to estimate the contribution of each action to the total reward:
… Total trajectory reward, which is the original REINFORCE weight. Unbiased but highest variance: every action is credited with the whole trajectory’s reward, including rewards collected before that it couldn’t have caused.
… Future reward after action (reward-to-go), drops the past rewards can’t influence. It’s variance is strictly lower, but the expectation stays the same. This is the standard REINFORCE form in practice.
… Baselined reward-to-go; is supposed to remove variance of the state, and focus the reward on the reward difference caused by actions in a specific state. does not bias the gradient, because it depends only on the state and not the action, so it cancels in expectation over actions (proof below).The above options pass a sampled return to : this is the last unbiased option.
The below instead passes a learned value function, trading bias (approximation error) for lower variance.… state-action value replaces the sampled return with its expectation. This is the actor critic move: a learned critic estimates , cutting variance a lot, but adding bias whenever the critic is imperfect.
… advantage function — with as the baseline. The sweet spot: near-lowest variance because it measures better/worse than the state’s average action directly (see below). De-facto target of modern methods (A2C/A3C, TRPO, PPO); never known exactly, so it’s estimated, usually via GAE.
… TD residual — a one-step, bootstrapped estimate of the advantage ( under the true ). Cheapest advantage: needs only , no separate -net. Most biased / most reliant on the value estimate; GAE dials between this (low variance, high bias) and the Monte-Carlo advantage (high variance, low bias) via .where
… state-value; expected total reward from state
… state-action value; expected total reward from state and action
Evolution Strategies
Link to originalNES
This paper uses NES, where an objective function acting on parameters is optimized. What makes it a natural evolution strategy is that we are not directly optimizing , but optimizing a distribution over parameters (“populations”) –itself parametrized by – and proceed to maximize the average objective value over the population by searching for with stochastic gradient ascent, using the score function estimator for similar to REINFORCE.
So gradient steps are taken on like this:We estimate the gradient by sampling the distribution because we can’t integrate over all possible values of .
Their population distribution is a factored gaussian, the resulting gradient estimator is known as “simultaneous perturbation stochastic approximation”, “parameter-exploring policy gradients”, and “zero-order gradient estimation” (zero order optimization).
The initial population distribution is an isotropic multivariate gaussian, with mean and fixed covariance .
Initially, we optimize which controls a population distribution that generates parameters . However, by fixing as a Gaussian with mean and variance , we can simplify this to directly optimizing by simply adding Gaussian noise during sampling. This transforms the problem from optimizing population distribution parameters () to directly optimizing the mean () of a fixed-form Gaussian, while maintaining exploration through noise injection. The resulting simplified gradient estimator:This noise / gaussian blurring also allows us to train on non-differential / unsmooth environments.
Link to originalNatural Evolution Strategies (NES)
Evolution strategies that use natural gradient descent to update search distribution parameters.
NES optimizes a probability distribution over parameters by maximizing expected fitness:Updates use the natural gradient where is the fisher information matrix.
This ensures the algorithm takes consistent steps in distribution space rather than parameter space - a small parameter change that drastically alters the distribution is scaled appropriately.
Financial Computations
…
Continue section 3 onwards after ALIFE, finishing probability rabbit hole, and maybe also after optimization bootcamp is out…
Link to original Footnotes
We will make one restriction in this review, and that is to problems where the measure is a probability distribution that is continuous in its domain and differentiable with respect to its distributional parameters.
Check out this epic visualization of how and convolve, and how the sensitivity guides the parameter optimization. ↩
Sensitivity here just means the gradient of an expectation, i.e. a measure of how much the expected value changes in response to small changes in parameters. Not really connected to the numerous other uses of the word sensitivity in other contexts, beyond the general idea of responsiveness to change. ↩

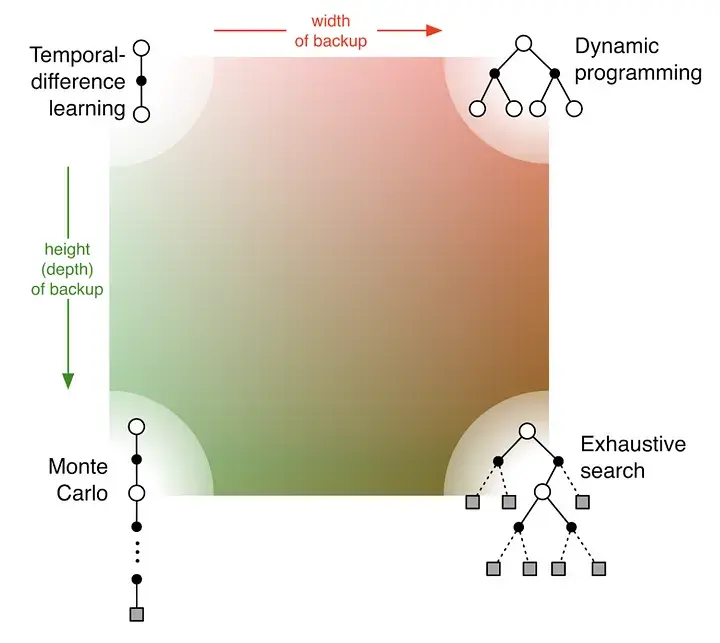
Link to originalThe picture shows the value propagation (“backup”) of a single update step with these three methods:
MC methods require complete episodes to learn, using actual returns to update value estimates. They’re unbiased (as long as there is exploration) but have high variance and require complete episodes (and thus more samples to achieve an accurate estimate, so bad for expensive environments), though truncated returns can also work.
TD bootstraps from existing value estimates after single steps, combining actual rewards with predicted future values. This introduces bias but reduces variance and enables online learning.
DP methods use the full model of the environment to consider all possible next states simultaneously, computing expected values directly. This is most sample-efficient (you don’t need to sample in order to approximate values – at the cost of exhaustive search) but requires a complete model of the environment, and are impractical for large state spaces, even with a perfect model (curse of dimensionality).
MC (left) vs TD
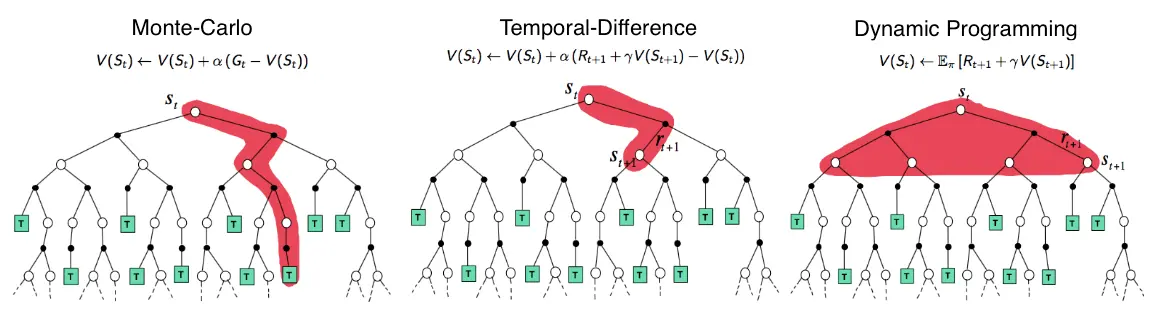
https://lilianweng.github.io/posts/2018-02-19-rl-overview/#monte-carlo-methods