year: 2021
paper: https://arxiv.org/pdf/2107.10394.pdf
website: https://starganv2-vc.github.io/
code: https://github.com/MaxWolf-01/real-time-vc
connections: GAN, style-transfer, cycle-consistency, voice conversion
Takeaways
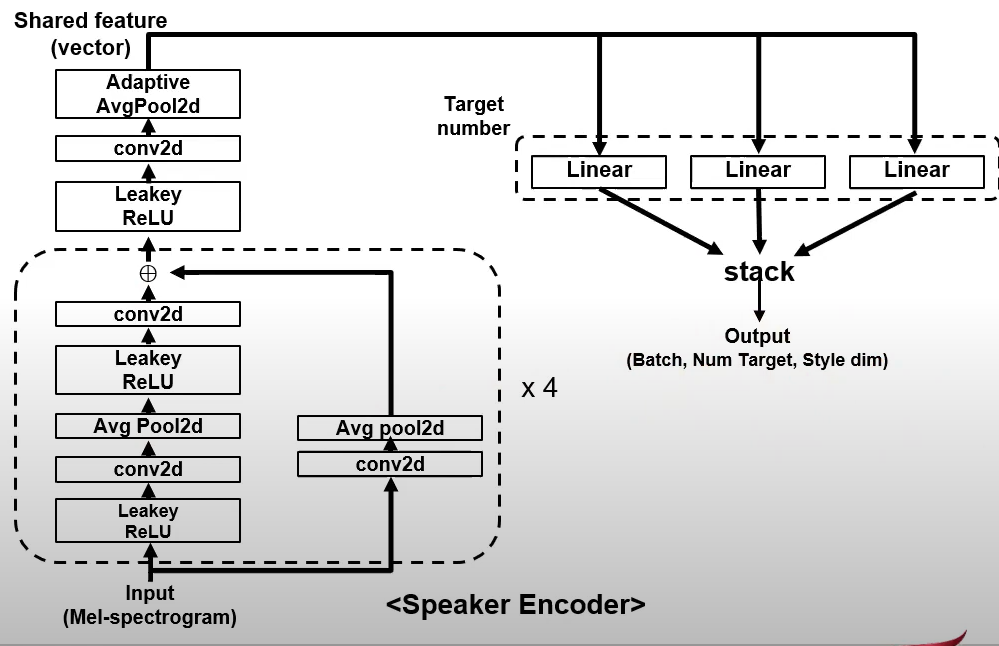
Style Encoder
Learns the style of a target speaker and encodes this style information in a “style-vector”.
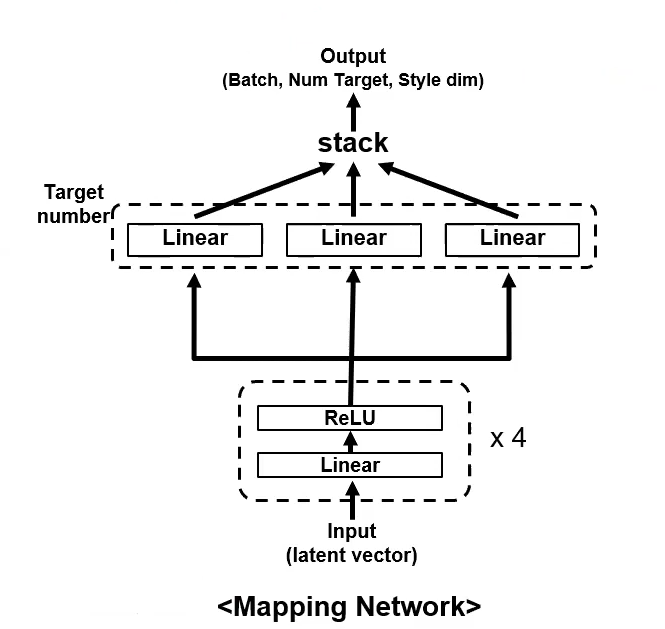
Mapping Nework
The mapping netowrk can be used to create the style vector instead of a style by reference mel-spectrogram from the Style Encoder. We sample from a random gaussian distribution.
Generator Encoder (Content encoder)
Filters the spectogram for only the linguistic / speech content
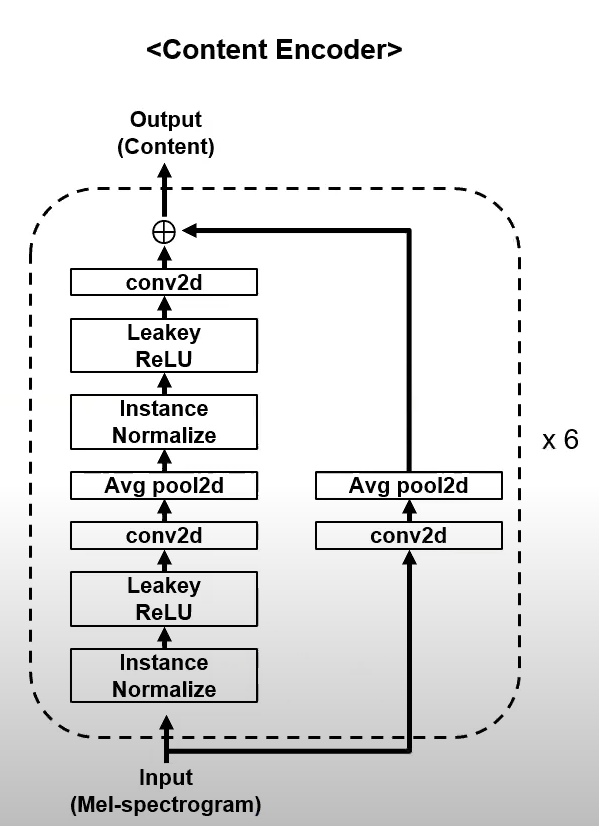
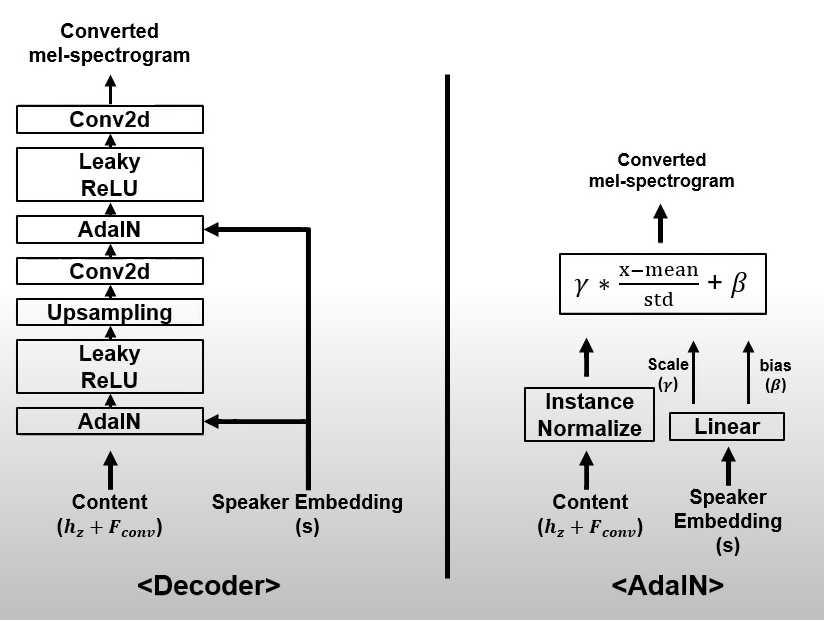
Generator Decoder
Turns latent representation + features of F0 Netork + Style vector into output mel-spectograms:
Losses
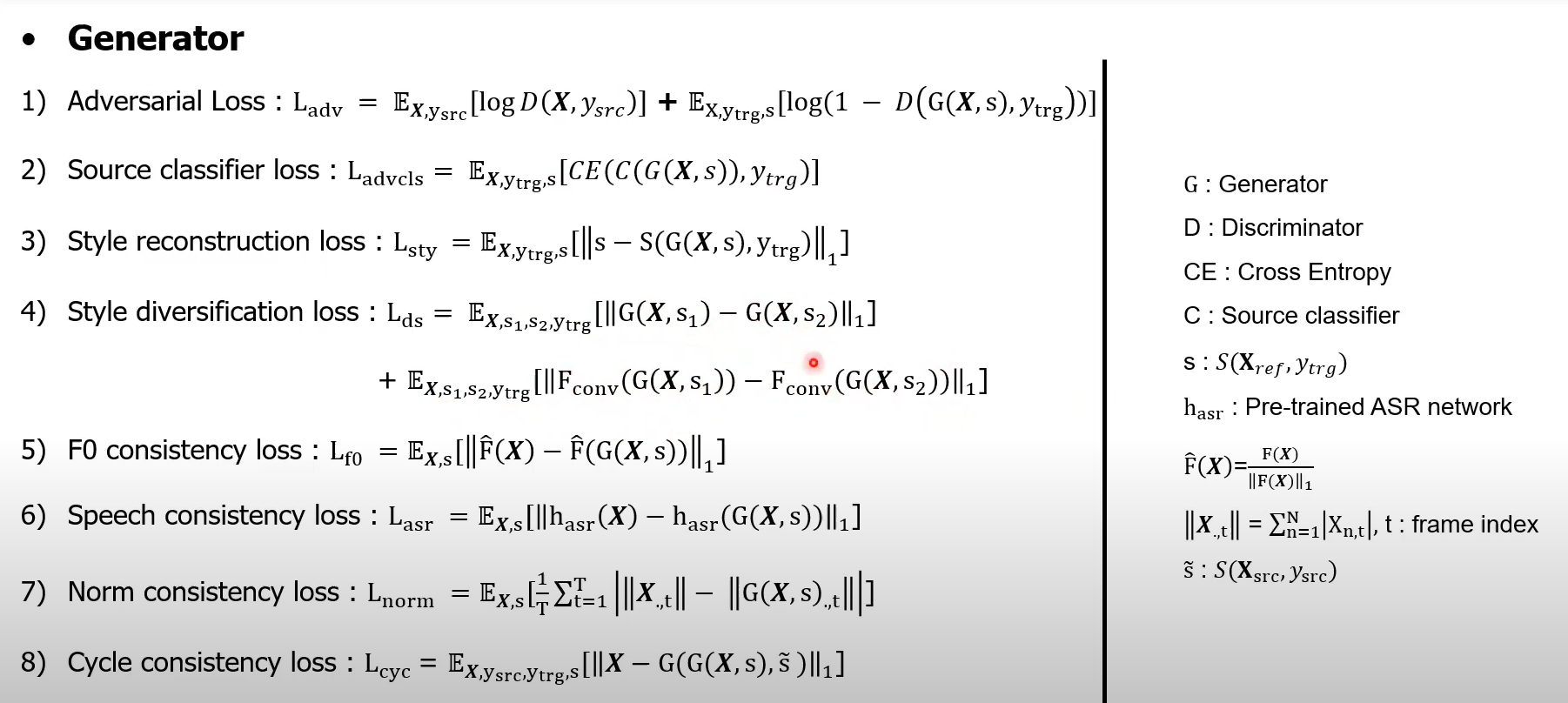

Training objectives
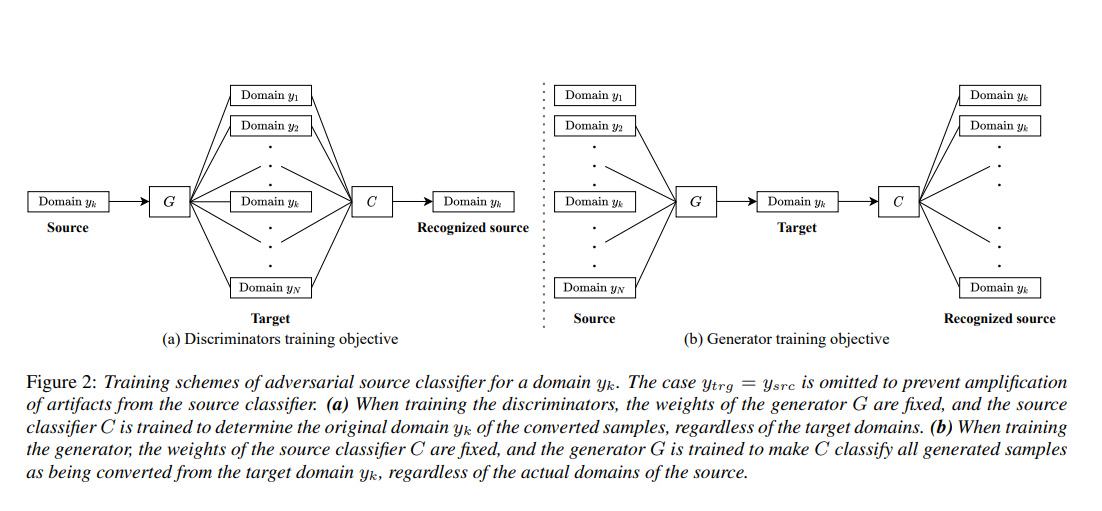
The discriminator (source classifier) tries to identify to which of the source domain the generated spectogram originally belonged to. It does not care about the target domain.
The generator tries to generate fake spectograms from one of the source domains (this domain is the target domain). It is successful if the classifier thinks that generated samples are from the target domain (but they are from a different domain).
2. Method in latex
2.1 StarGANv2-VC
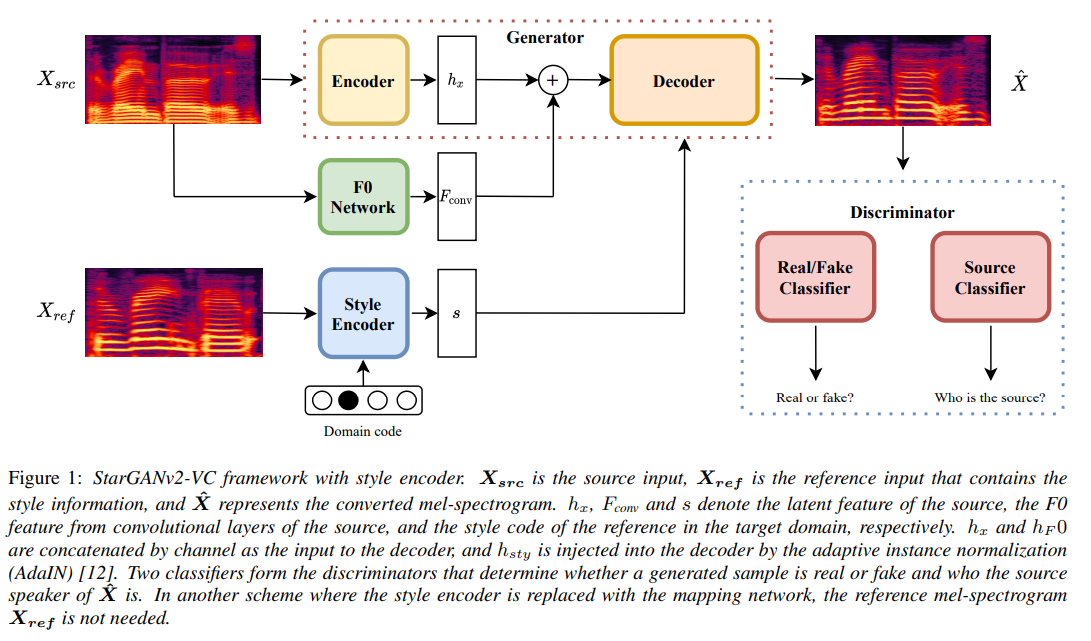
StarGAN v2 [10] uses a single discriminator and generator to generate diverse images in each domain with the domainspecific style vectors from either the style encoder or the mapping network. We have adopted the same architecture to voice conversion, treated each speaker as an individual domain, and added a pre-trained joint detection and classification (JDC) F0 extraction network [13] to achieve F0-consistent conversion. An overview of our framework is shown in Figure 1. Generator. The generator converts an input mel-spectrogram Xsrc into that reflects the style in , which is given either by the mapping network or the style encoder, and the fundamental frequency in , which is provided by the convolution layers in the F0 extraction network . F0 network. The F0 extraction network is a pre-trained JDC network [13] that extracts the fundamental frequency from an input mel-spectrogram. The JDC network has convolutional layers followed by BLSTM units. We only use the convolutional output for as the input features. Mapping network. The mapping network generates a style vector with a random latent code in a domain . The latent code is sampled from a Gaussian distribution to provide diverse style representations in all domains.
The style vector representation is shared for all domains until the last layer, where a domain-specific projection is applied to the shared representation. Style encoder. Given a reference mel-spectrogram , the style encoder S extracts the style code in the domain . Similar to the mapping network M, S first processes an input through shared layers across all domains. A domain-specific projection then maps the shared features into a domain-specific style code. Discriminators. The discriminator in [10] has shared layers that learns the common features between real and fake samples in all domains, followed by a domain-specific binary classifier that classifies whether a sample is real in each domain . However, since the domain-specific classifier consists of only one convolutional layer, it may fail to capture important aspects of domain-specific features such as the pronunciations of a speaker. To address this problem, we introduce an additional classifier with the same architecture as that learns the original domain of converted samples. By learning what features elude the input domain even after conversion, the classifier can provide feedback about features invariant to the generator yet characteristic to the original domain, upon which the generator should improve to generate a more similar sample in the target domain. A more detailed illustration is given in Figure 2.
2.2 Training Objectives
The aim of StarGANv2-VC is to learn a mapping that converts a sample from the source domain to a sample in the target domain without parallel data.
During the training, we sample a target domain and a style code randomly via either mapping network where with a latent code , or style encoder where with a reference input . Given a mel-spectogram , the source domain and the target domain , we train our model with the following loss functions:
Adversarial loss 1
The generator takes an input mel-spectrogram and a style vector and learns to generate a new mel-spectrogram via the adversarial loss.
where denotes the output of real/fake classifier for the domain .
Adversarial source classifier loss
We use an additional adversarial loss function with the source classifier C (see Figure 2).
where denotes the cross-entropy loss funtion
Style reconstruction loss
We use the style reconstruction loss to ensure that the style code can be reconstructed from the generated samples.
Syle diversification loss
The style diversification loss is maximized to enforce the generator to generate different samples with different style codes. In addition to maximizing the mean absolute error (MAE) between generated samples, we also maximize MAE of the F0 features between samples generated with different style codes
where are two randomly sampled style codes from domain and is the output of the convolutional layers of the F0 network .
F0 Consistency Loss
To produce F0-consistent results, we add an F0-consistent loss with the normalized F0 curve provided by F0 network . For an input mel-spectrogram provides the absolute F0 value in Hertz for each frame of . Since male and female speakers have different average F0, we normalize the absolute F0 values by its temporal mean, denoted by . The F0 consistency loss is thus:
Speech consistency loss
Speech consistency loss. To ensure that the converted speech has the same linguistic content as the source, we employ a speech consistency loss using convolutional features from a pretrained joint CTC-attention VGG-BLSTM network [14] given in Espnet toolkit 1 [15]. Similar to [16], we use the output from the intermediate layer before the LSTM layers as the linguistic feature, denoted by . The speech consistency loss is defined as
Norm consistency loss
We use the norm consistency loss to preserve the speech/silence intervals of generated samples. We use the absolute column-sum norm for a mel-spectrogram with mels and frames at the frame, defined as , where is the frame index. the norm consistency loss is given by
Cycle consistency loss 2
Lastly, we employ the cycle consistency loss to preserve all other features of the input
where is the estimated style code of the input in the source domain .
Full objective
Our full generator obbjective functions can be summarized as follows:
where and are hyperparameters for each term.
Our full discriminators objective is given by:
where is the hyperparameter for source classifier loss which is given by
Figures
Figure 1:
StarGANv2-VC framework with style encoder. is the source input, is the reference input that contains the style information, and represents the converted mel-spectrogram. and denote the latent feature of the source, the F0 feature from convolutional layers of the source, and the style code of the reference in the target domain, respectively. and are concatenated by channel as the input to the decoder, and hsty is injected into the decoder by the adaptive instance normalization (AdaIn) [12]. Two classifiers form the discriminators that determine whether a generated sample is real or fake and who the source speaker of is. In another scheme where the style encoder is replaced with the mapping network, the reference mel-spectrogram is not needed.
Figure 2:
Training schemes of adversarial source classifier for a domain . The case is omitted to prevent amplification of artifacts from the source classifier. (a) When training the discriminators, the weights of the generator are fixed, and the source classifier is trained to determine the original domain yk of the converted samples, regardless of the target domains. (b) When training the generator, the weights of the source classifier are fixed, and the generator is trained to make classify all generated samples as being converted from the target domain , regardless of the actual domains of the source.
Additional resources
These issues will be valuable for improving / debugging gan training later: https://github.com/yl4579/StarGANv2-VC/issues/21 # Inference with nois source https://github.com/yl4579/StarGANv2-VC/issues/6 # “Many to many doubts” / improve zero-shot by adding more F0 ResBlocks https://github.com/yl4579/StarGANv2-VC/issues/68 # adding more discriminators
A previous pasper on improving StarGAN-V2TOWARDS LOW-RESOURCE STARGAN VOICE CONVERSION USING WEIGHT ADAPTIVE INSTANCE NORMALIZATION
Korean only… video that has diagrams for architecture at least (I have half assed transcript with whisper now).
References
GAN
Joint Detection and Classification of Singing Voice Melody Using Convolutional Recurrent Neural Networks
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks (→ big part of this paper)
Footnotes
-
[[Generative Adverserial Nets#Minmax loss [ src1|Minmax loss]] ↩
-
↩
Link to originalCycle Consistency
The idea of using transitivity as a way to regularize structured data has a long history. In visual tracking, enforcing simple forward-backward consistency has been a standard trick for decades. In the language domain, verifying and improving translations via “back translation and reconciliation” is a technique used by human translators.