Link to originalReservoir computing
In 2001 a fundamentally new approach to RNN design and training was proposed independently by Wolfgang Maass under the name of liquid state machines and by Herbert Jaeger under the name of echo state networks. This approach is now often referred to as the Reservoir Computing Paradigm.
Reservoir computing also has predecessors in computational neuroscience (see Peter Dominey’s work in section 3.1) and in machine learning as the Backpropagation-Decorrelation learning rule proposed by Schiller and Steil in 2005. As Schiller and Steil noticed, when applying BPTT training to RNNs the dominant change appear in the weights of the output layer, while the weights of the deeper layer converge slowly.
It is this observation that motivates the fundamental idea of Reservoir Computing: if only the changes in the output layer weights are significant, then the treatment of the weights of the inner network can be completely separated from the treatment the output layer weights.
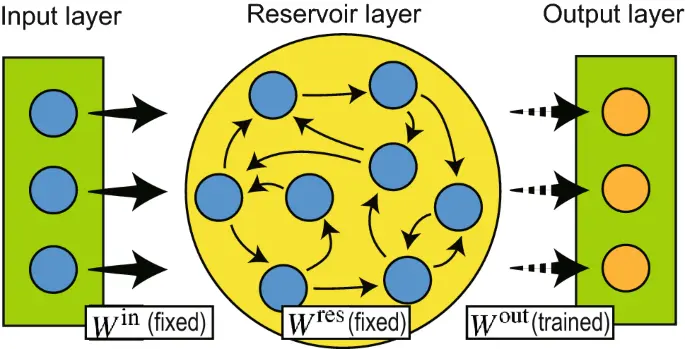
The Echo State Networks (ESNs) method, created by Herbert Jaeger and his team, represents one of the two pioneering reservoir computing methods.
Having observed that if a RNN possesses certain behavioral properties (separability and echo state), then it is possible to achieve high classification performance on practical applications simply by learning a linear classifier on the readout nodes, for example using logistic regression. The untrained nodes of the RNN are part of what is called the dynamical reservoir, which is where the name Reservoir Computing comes from. The Echo State names comes from the input values echoing throughout the states of the reservoir due to its recurrent nature. Because ESNs are motivated by machine learning theory, they usually use sigmoid neurons over more complicated biologically inspired models.